
Applying GPU to Snap
At Snap, we apply the latest ML technology to find engaging content and relevant ads. ML plays a central role in delivering long-term values to Snapchatters, Creators and our advertisers. In this blog, we share our experiences and insights in applying the GPU technology to accelerate ML model inference. Inference refers to the computation-intensive process of calculating model predictions (such as the probability that a Snapchatter completes watching a video) from input features (such as the number of videos that the Snapchatter watched in the past hour). This is particularly challenging at Snap...
The current success of ML and particularly DNN can be attributed to 3 trends taking place concurrently:
Years of buildup of large-scale datasets and steady improvement of label quality;
Efficient ML algorithms that can scale to these datasets, especially Stochastic Gradient Descent (SGD) and its variations that achieve both great efficiency and accuracy;
Last but not least, the emergence of specialized hardware accelerators whose performance outpaces Moore's law in the ML application domain.
On Snapchat, we have evolved our ML models to be based on DNN, which are more accurate but also exceptionally computation-hungry. We have built a highly scalable and efficient inference stack within the x86-64 CPU ecosystem to meet this challenge. And we are constantly looking to optimize our inference stack for several reasons:
Our community keeps growing and they interact with our app more frequently. ML prediction is behind everything that we show to Snapchatters, from a friend’s Story to an entertaining Snap Original, and from a hilarious Spotlight video to a fashion commercial. Each time Snapchatters open our app, tens of thousands of ML predictions are performed to pick personalized real time content, ensuring that they have the best experience.
Internally, many teams increasingly rely on ML technology to deliver innovative features to Snapchatters while adhering to our stringent privacy standard. As ML engineers, we are excited to see that the platform that we build is powering more and more products. But we are also acutely aware of the limits of our current platform and constantly look for new ways to 10x our capabilities without consuming 10x of the resources!
With the arrival of inference-oriented accelerators such as the NVIDIA T4 GPU device, we started to investigate whether they can offer a better tradeoff between performance/scalability and cost.
It is remarkable that the amount of compute provided by modern GPUs has increased 25 fold in a period of 5 years, whereas Moore’s law would only predict 10 fold [1]. In terms of performance per dollar or performance per watt, accelerators dominate top ranks in public benchmarks [2]. Recently NVIDIA GPUs and the CUDA toolkit have become the commodity platform for demanding ML training and inference tasks. They were behind the early success of AlexNet [3] in Computer Vision and also the latest 100B+ parameter language models [4] in Natural Language Processing.
Compared with CPUs, GPUs provide over an order of magnitude higher raw throughput of floating point operations (FLOPS) and also moderately higher memory bandwidth. Empirically, low-precision arithmetics do not affect DNN training and inference accuracy significantly [5], and GPUs offer another order of magnitude higher throughput when low-precision arithmetics such as FP16 are used. In terms of performance per dollar, GPUs are convincingly more efficient for ML inference. We estimate that cloud GPU machines can offer 2-3x the peak throughput per dollar versus the best cloud CPU machines available.
Different model architectures yield different mixtures of arithmetic and memory operations, and accordingly exhibit different amounts of improvement on GPUs. Here we analyze a typical ranking model that we use on Snapchat. This type of model consumes most of our ML inference resources. For the ease of presentation, the following diagram is significantly simplified.
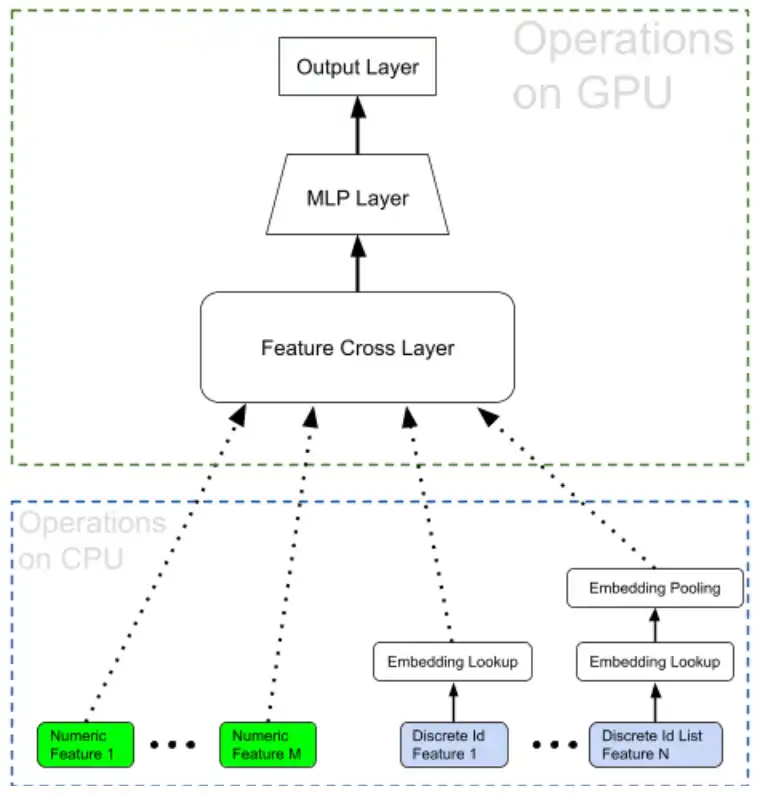
Discrete id features are first converted into low-dimensional vectors, i.e., embeddings. We also use discrete id list features such as the list of ads that a user saw in the last 10 minutes. These list features first become variable length lists of embeddings after embedding lookup. And the lists of embeddings are further aggregated through pooling layers. Embeddings and numeric features are concatenated together and then fed into our feature cross layer. The output of feature crossing is then compressed through a Multi-Layer Perceptron (MLP) layer. It is worth mentioning that the heaviest parts in terms of computation of our model are the feature cross and the MLP layers. Their computation scales with the square of the input width. But the overall memory IO only scales linearly with the input width. Given the much higher throughput of arithmetics, in general, wider models exhibit higher speedup when migrated to GPUs. Another optimization demonstrated in this figure is that we offload the operations that perform large amounts of memory IO to CPUs and allow GPUs to focus on computation-intensive operations. This is also a huge win for inference workloads in practice.
We chose the NVIDIA T4 GPU as our target device because it is specifically designed for inference workloads and also widely available. For the compiler and runtime suite, we investigated the performance and flexibility tradeoff for TensorRT [6] and TensorFlow XLA [7]. TensorRT is NVIDIA's own inference optimizer and runtime toolkit, which provides a rich set of low-level interfaces for performance tuning. XLA stands for Accelerated Linear Algebra and as its name suggests, it is a compiler that converts generic linear algebra operations into high performance binary code. The binary code can target CPUs or ML accelerators. From our experience, XLA excels at optimizing graph substructures such as multi-operation fusion, which is critical for some of our production models.
We first benchmarked models that are dominated by matrix multiplication, which serves as headroom analysis because it is the optimal workload for GPUs. We use the following calculation designed to perform a large number of arithmetic operations while keeping the input and output sizes small: y = (x ⊕ aᵀ)Bc
where x is the input vector of dimension d, a and c are constant vectors of the same dimension, and B is a constant d by d matrix. The addition operation is an outer addition, i.e., the result of adding a column vector and a row vector of dimension d is a d by d matrix. The number of FLOPS in the above calculation is approximately 2d³, while the input and output are both d-dimensional vectors.
Our benchmarking CPU virtual machine (VM) is a 60 CPU machine from our cloud provider and GPU VM is a 64 CPU machine with 4 T4 GPU devices. We will keep the same hardware setup in all following benchmarks. We measure the sustained Tera-FLOPS (TFLOPS) numbers, absolute and relative to the theoretical peak throughput. We benchmarked this simple model with varying dimensions in our production environment to ensure that these utilization metrics are achievable in practice.
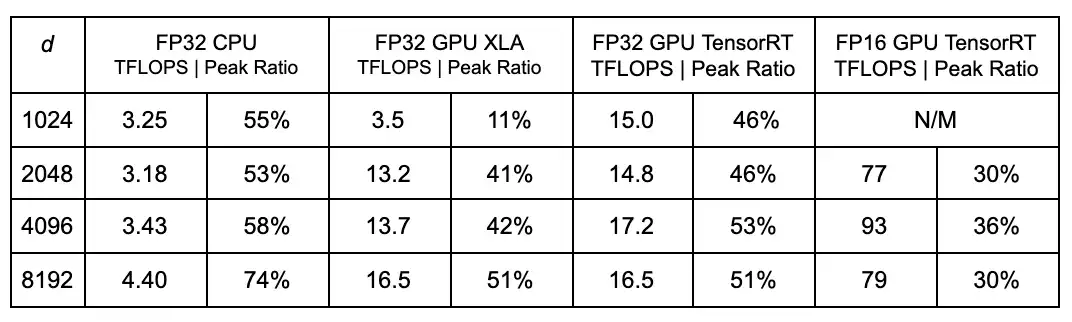
N/M means “not meaningful” as the performance bottleneck is not the arithmetic operations in these settings. FP32 refers to the 32 bit IEEE754 floating point number format and FP16 is NVIDIA's proprietary 16 bit floating point number format.
We highlight following findings from these experiments:
With FP32, we can achieve ~4x better throughput on GPUs. With FP16, the advantage exceeds 15x;
In general, the higher the dimension, the better utilization ratio on GPUs, which matches our previous analysis of the mixture of arithmetic and memory operations;
TensorRT performs observably better at lower dimensions than XLA and;
Lastly, throughput with FP16 is significantly higher than with FP32, however FP16 incurs slight precision loss. The exact model quality impact is model dependent and we don’t plan to apply FP16 to all of our models.
Looking at the previous GPU benchmark numbers, we come to the conclusion that our current ML inference workloads will benefit greatly from GPU acceleration. We integrate GPU accelerator support from our cloud providers into our ML inference platform. Next, we will describe a few unique engineering solutions that we have developed for cloud-based GPU inference.
GPUs can significantly speed up models that are dominated by large matrix multiplications. However we have a wide range of models that present very different bottlenecks when applying GPU optimization:
Our models can have a large number of memory intensive operations such as: embedding lookup, concatenation, stacking and tiling. These are relatively expensive on GPUs in comparison with arithmetics. As we mentioned previously, we place these operations on CPUs to achieve better efficiency.
Small operations tend to under-utilize GPU cores, hence when a computation graph is made up of many small operations, its overall utilization degrades significantly. It can be addressed with operation fusion (automatically by XLA) or model rewriting (manually).
From the beginning, we made a design-decision to make the GPU inference details completely transparent to engineers who work on ML models. To this end, we built an automatic model translation workflow that applied multiple customizable GPU optimization steps to our DNN models. We encapsulated this workflow into a single job executed by our Kubernetes workers and invoked it after training completion without manual intervention.
We now present a specific use case of our translation flow that improves inference performance automatically at scale. A large number of our ranking DNN models make use of mixtures of experts (MoE) [8] and each expert is in general a light operation, which keeps the total computation within budget. Through benchmarks, we observe that with XLA’s built-in fusion of multiple operations, we can achieve higher throughput than with TensorRT. So we have built a model compilation step that combines XLA’s fusion facility and other low level optimization techniques. This step is then automatically triggered when we detect that the model under optimization uses MoE layers.
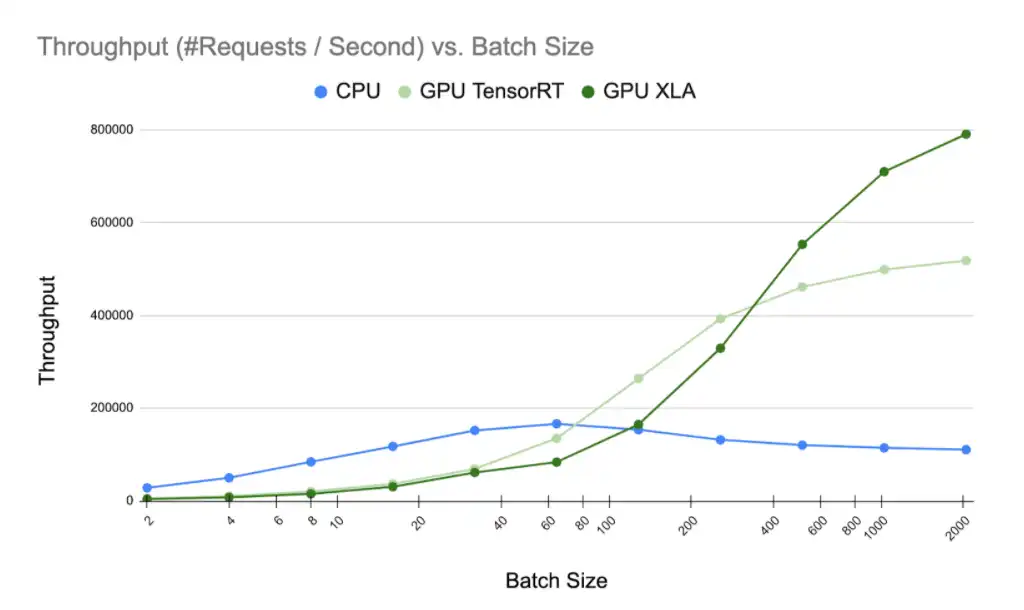
In the figure above, we demonstrate the inference performance of one of our MoE models that benefits from our XLA compilation step significantly. We measured the model inference throughput under different batch sizes for CPU, GPU TensorRT and GPU XLA configurations. With large batch sizes, XLA significantly outperforms TensorRT by a margin of 20-50%. The relative underperformance of XLA when the batch size is below 256 is due to the fixed scheduling costs that can’t be amortized away with small batch sizes. Another interesting observation is that the CPU throughput exhibits a peak at the batch size of 64, which is likely when CPU cache overflow occurs.
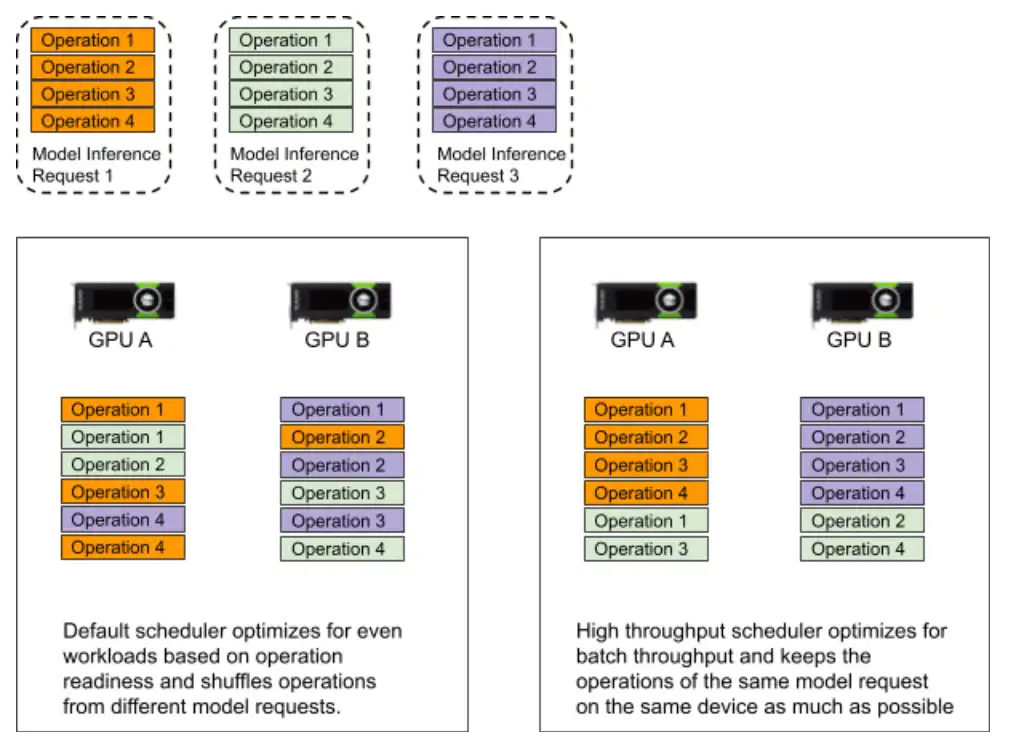
In a cloud environment, it is beneficial to allocate multiple GPU accelerators per VM as CPU, RAM and network resources can be better utilized when shared among them. But this also creates an often-neglected issue of scheduling GPU operations to GPU devices. By default, ML inference frameworks such as TensorFlow Serving schedule operations evenly to all devices available as soon as they are ready. This ensures reasonable utilization of GPUs under a wide range of workloads. On the other hand, we observe that we can achieve much better throughput when we schedule the operations from the same model request to the same device. And we also know that our inference requests arrive continuously in batches. So we always have sufficient workload to keep GPUs highly utilized even when we restrict ourselves to sending the operations from the same request to the same device. After realizing this, we custom built the GPU operation scheduler to enable this performance gain. We illustrate such an example in the figure below. Suppose we have 3 model inference requests, and each contains 4 operations and we have 2 GPU devices A and B to execute these operations.
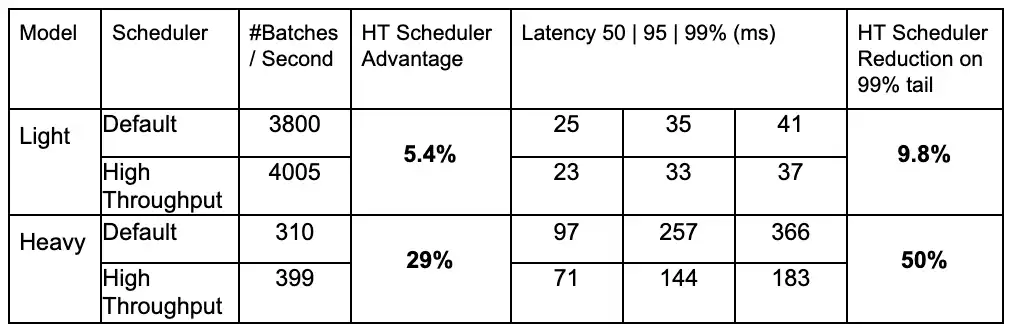
We choose two complement models, one computationally lighter and the other much heavier in comparison. Throughput and tail latencies are two of the most important performance metrics for our production serving systems. From the table above, we observe that with the custom GPU scheduler, we manage to improve throughput by 29% and tail latency by 50% on the heavy model.
Finally, we present the measured impact of GPU acceleration from our production workloads. We measure the same light and heavy models under a batch size of 500, which is close to our production.
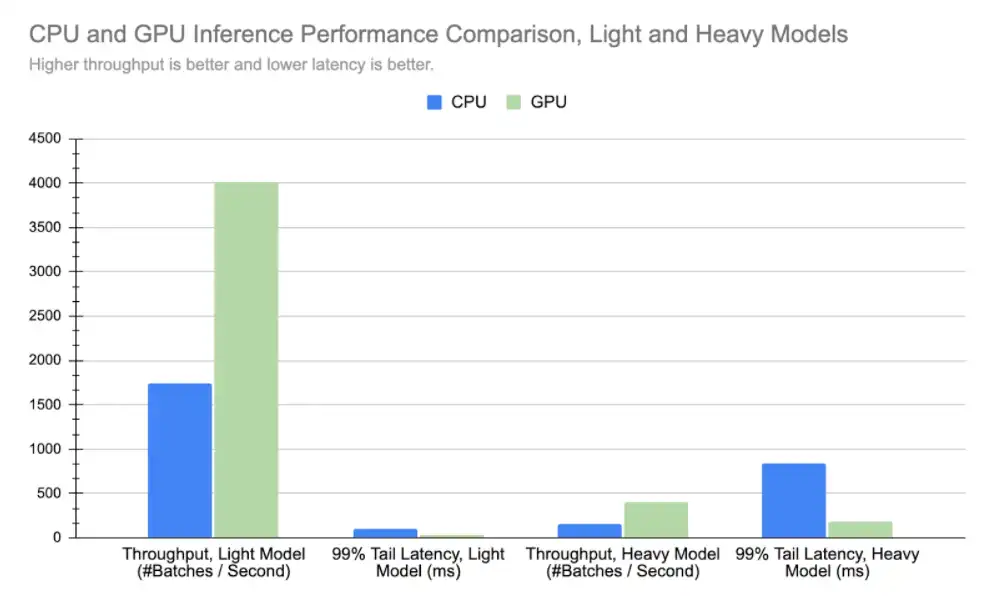
We measured everything using our production setup, which included our customized feature fetching/caching logic. We keep the most frequently used feature values cached on the same machines as the inference threads.
Based on the on-demand prices for CPU and GPU VMs, GPU VMs can sustain more than 1.3x throughput at the same dollar cost as CPU VMs.
We also benchmarked the performance of the heavy model under the normal batch size(500) and double (1000). As expected, we observe much better performance improvement for GPUs under larger batch sizes.
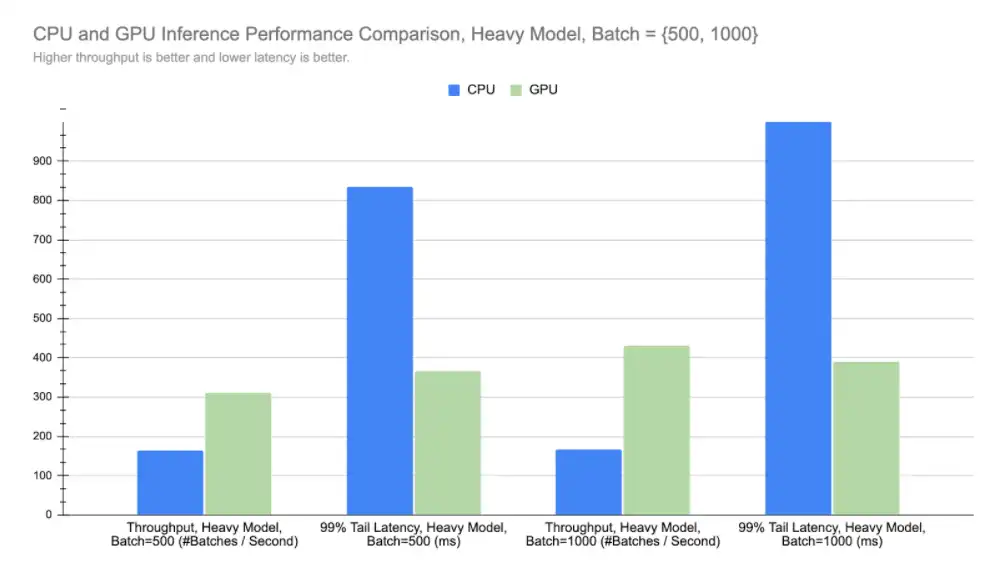
In this chart, we report one 1000-request batch as two 500-request batches. It is worth highlighting that with double batch sizes, GPU VMs offer more than 1.7x throughput at the same cost now.
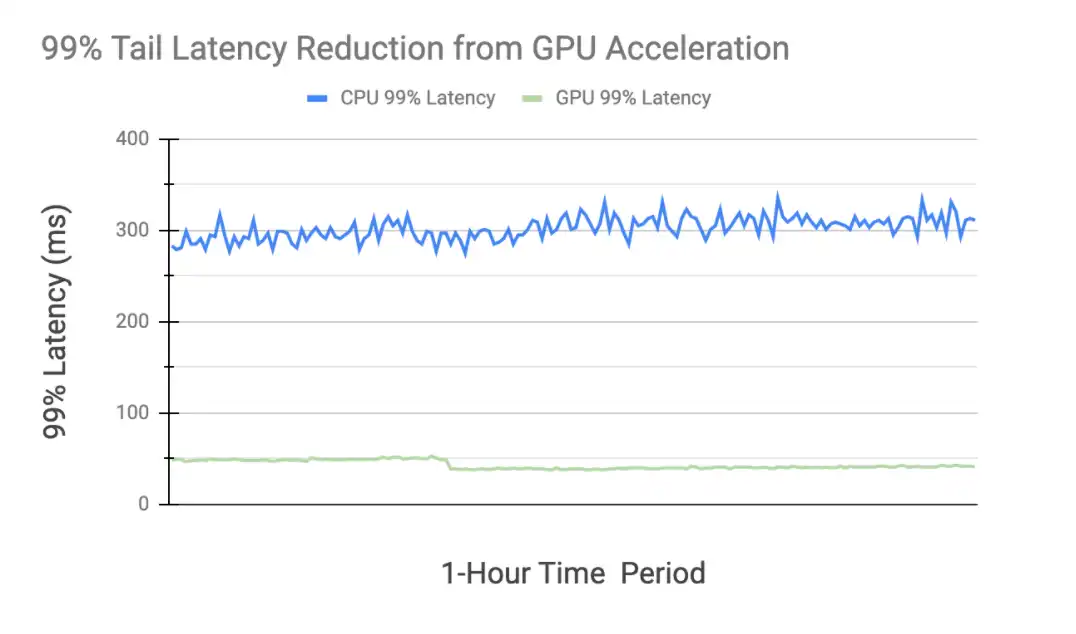
Lastly, we show two 1-hour time series of 99% tail latencies in our production environment, one for CPU inference and the other for GPU. This presents a snapshot of tail latencies of a large collection of our ML production models. The tail latency is over 6x better with GPU inference under this workload.
In this blog, we shared our experiences and insights in applying the GPU technology to accelerate ML model inference on Snapchat. We described our engineering solutions to realize better performance per dollar from GPU acceleration. We hope that this blog sheds light on the challenging yet critical inference stack in an ML production environment. Our exploration in this direction will continue and we look forward to sharing more of our discoveries in the future!
___________________________________
¹ Snap Inc. internal data as of August 11, 2021
[3] Krizhevsky et al., “ImageNet Classification with Deep Convolutional Neural Networks”, NIPS 2012
[4] Brown et al., “Language Models are Few-Shot Learners”, NeurIPS 2020
[5] Courbariaux et al., “TRAINING DEEP NEURAL NETWORKS WITH LOW PRECISION MULTIPLICATIONS”, ICLR (workshop) 2015
[8] Ma et al., “Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts”, KDD 2018