CodePal: How Snap Built an AI Code Reviewer for the Age of AI-Written Code
AI coding tools have fundamentally changed how software gets written. At Snap, engineers use tools like Cursor and Claude Code daily, and the impact on velocity has been real.
Year-to-date, our merged (Pull Request) PR rate is up 60%.
But there's a catch. When everyone can produce code faster, the bottleneck doesn't disappear, it shifts. And at Snap, it moved squarely onto the code review process.
We were seeing more PRs, larger PRs, and reviewers stretched thinner across all of these additional reviews. As a result, review queues backed up, and merge times grew. Faster code creation without faster code review is a recipe for technical debt.
So we built CodePal, Snap's internal AI-powered code review assistant. Our goal was to build a highly intelligent, AI code review system which understands exactly how we work at Snap, giving PR authors real, valuable, quick feedback on their work, in order to reduce the PR review burden on their teammates. Our vision is a code reviewer that engineers consistently collaborate with as part of the software development lifecycle.
Today, CodePal reviews 90% of all PRs at Snap, even before a human reviews them.

Why We Built It Ourselves
We evaluated several vendor solutions before deciding to build in-house. The landscape of AI code review tools is increasingly crowded and all offer compelling capabilities. But for Snap's needs, they fell short in two critical areas.
First, integration depth: Snap's engineering infrastructure is extensive and deeply interconnected. Our build systems, deployment pipelines and internal tooling all have specific requirements that off-the-shelf tools can't easily accommodate. CodePal needed to understand Snap-specific proto definitions, our internal configuration systems, and the nuances of working across hundreds of services. We needed very specific team-level customizations that most tools offered a portion of, but didn’t offer everything we needed. A generic tool with only a few configuration knobs wasn't going to work for us.
Second, speed: We shipped a working end-to-end demo in two weeks. A vendor procurement cycle hadn't even finished. And from week one, CodePal reviewed its own pull requests, which surfaced issues faster than any human review could.
What CodePal Does
At its core, CodePal starts with the code diff like any other code reviewer but now it has deep symbolic context across the repository, and for a growing share of reviews, across repositories. It goes well beyond surface-level checks. Part 2 covers the cross-repo capability in depth.

For a growing portion of reviews, CodePal also reaches across repository boundaries via Code Search, an internal semantic search system covering Snap's full codebase. Before a function signature change merges, CodePal can identify the downstream callers that would break, even when they live in a different repo than the one the PR touches. This has already caught real cross-repo breakages before they merged, bugs no reviewer looking only at the diff could have flagged. Part 2 covers Code Search in depth, including how we integrated it into CodePal.
CodePal looks for issues that aren't typically caught by compilation or test suites: logic errors, null pointer risks, race conditions, resource leaks, error handling gaps, type mismatches, edge cases, and state management problems. For some repositories, it applies additional checks that are specific to that repo so that reviews can be tailored towards exactly what it needs.
Engineers consistently validate CodePal’s findings, and the majority of accepted bugs (bugs with a +1 vote in the PR review) found by CodePal rank as Critical or High severity. These are issues that, without CodePal, would have needed to have been caught by the human reviewer to ensure they don’t reach production. It has also allowed us to identify potential performance-related findings during development, prior to release.
Beyond line-by-line analysis, CodePal generates semantic diff summaries that explain what a PR does and why, giving reviewers a high-level understanding before they dive into the code. It can also auto-generate PR descriptions, titles, and structured sections like release notes or migration steps, all inferred directly from the code changes.
These features save significant time for both authors and reviewers. Instead of spending the first ten minutes of a review figuring out what a PR is doing, reviewers can jump straight to evaluating whether the approach is correct. These outputs, review findings, semantic summary, generated description, all flow from the same context build, which we'll cover below.
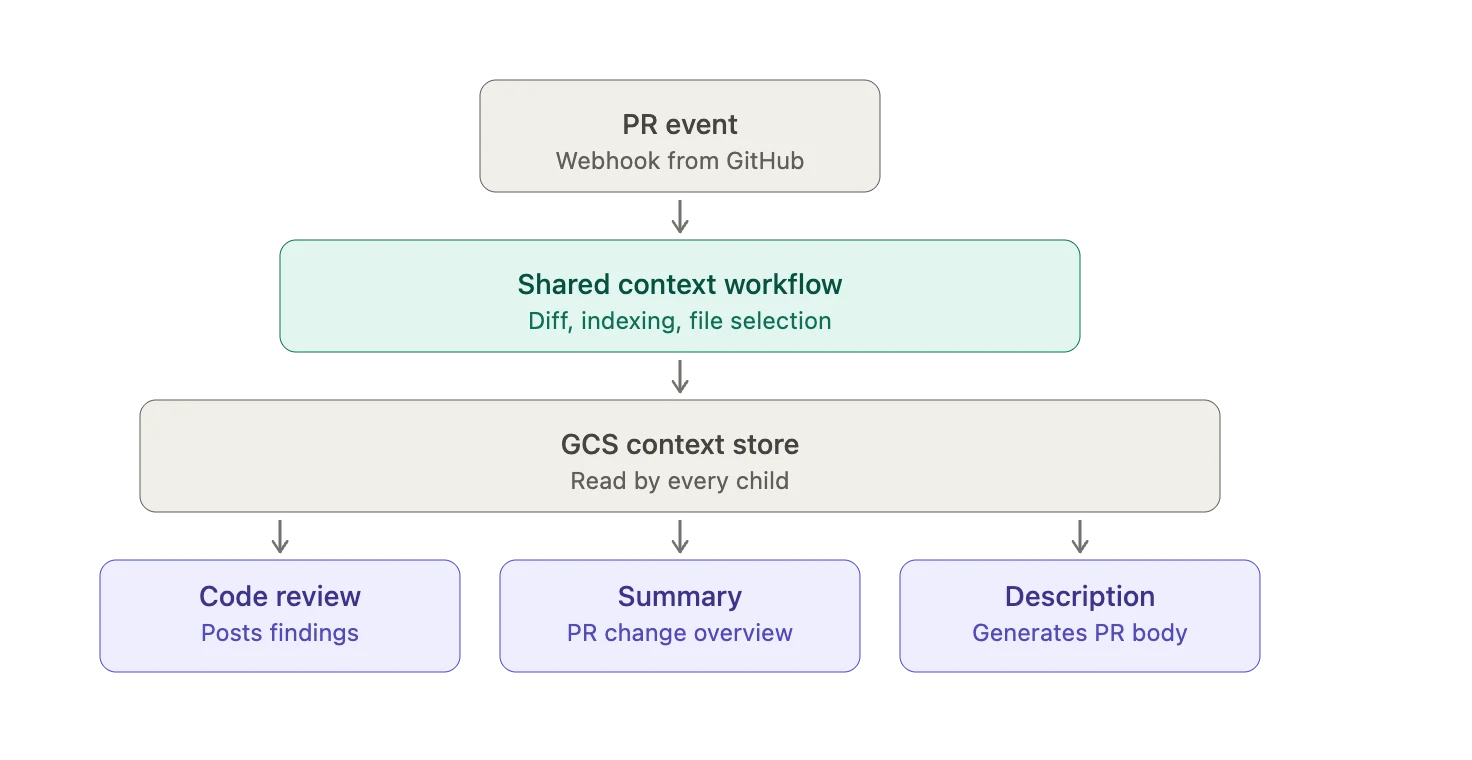
Building Code Context
A diff in isolation is almost always the wrong unit to reason about. A line that adds return user.Profile.Email looks fine until you know that Profile is nullable on this code path, which you can only learn by reading three files the diff never touches. Most AI review tools either ignore this, and miss real bugs, or stuff the entire repository into the prompt and pay for tokens that don't help. CodePal does neither.
CodePal solves this using a two-pass approach. The first pass parses the repository with tree-sitter to build a symbol-to-file index. The second pass analyzes the diff, extracts referenced symbols, looks them up in the index, and scores files by symbol overlap. This scoring selects the top N most relevant files within the token budget. CodePal doesn't just see what changed; it understands the code first.

Before describing what CodePal does with the code, it's worth noting what it doesn't do: clone the repository. Every review runs entirely in memory, against the GitHub Enterprise (GHE) API. We never check out a working copy, never write source to disk, and never hold a long-lived mirror of any repository. This was a deliberate constraint, not a limitation. Cloning Snap's largest repos is slow and expensive in both time and storage. At the rate CodePal runs reviews, a clone-per-review architecture would have melted either our infrastructure or our GHE instance. Instead, we lean on git tree diffs to identify what changed, fetch only the specific blobs we need, and let the two-pass file picker keep the working set small. A typical review touches a handful of API calls and a few hundred KB of source, regardless of repo size. Without that, none of the rest of this would scale.
This approach provides an architectural payoff. One parent workflow executes the expensive symbol indexing and file selection process just once, writing the resulting context to a shared store. Three child workflows, which handle code review, summary generation, and description generation, then all read from this single, shared context. The summary and description products effectively come for free; they're paying for storage, not for context. This shared store design will also be critical for Part 2, as Code Search will plug into the same system.
The Review Loop
The naive way to generate an AI code review is to send the diff and context to a model and ask it for findings. We tried that. It works, sort of. The model finds real bugs, but it also makes things up, contradicts itself between runs, and produces wildly different findings depending on the random seed. We needed a review loop that was both more thorough and more consistent than a single model call.
The solution is a multi-stage, iterative process we call the Review Loop, which is central to what makes CodePal novel.
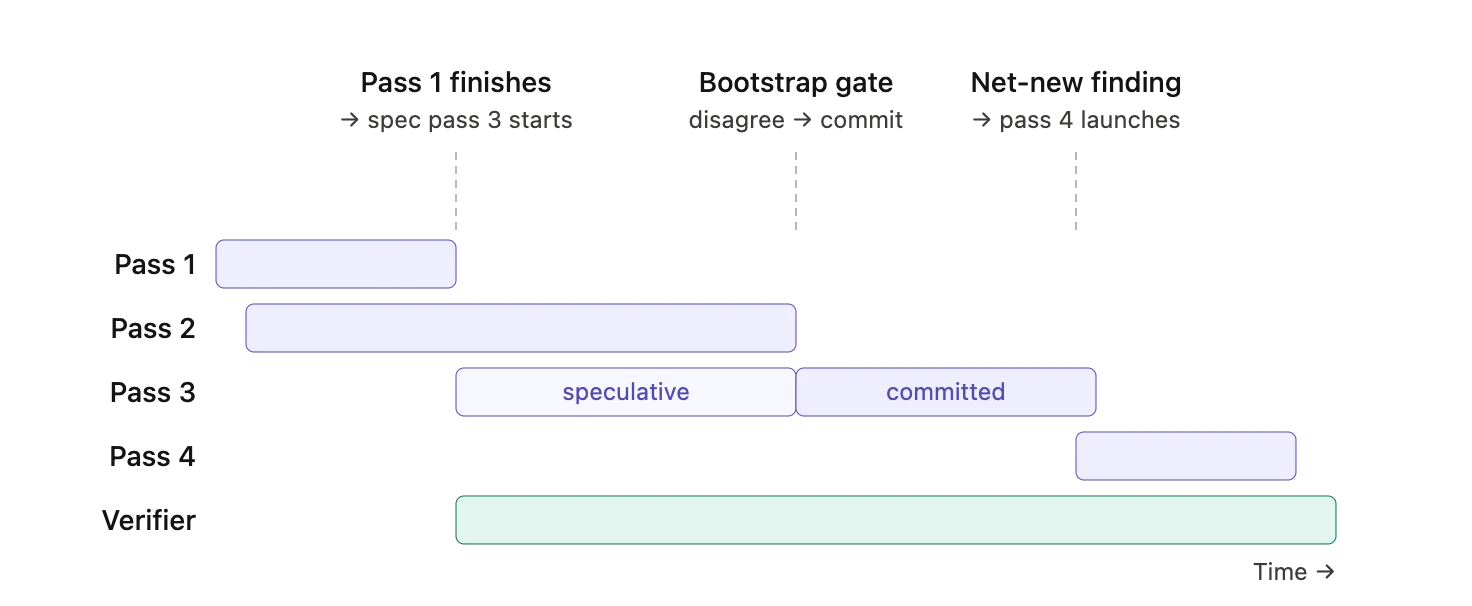
Two passes run in parallel from the start. They use the same model but different sampling parameters. The model's primary role is to find bugs. Running it twice and comparing the results tells us which findings the model actually believes.
The moment one bootstrap pass finishes, a third pass launches into a cancellable context, work it might throw away. When both bootstrap passes complete, the supervisor compares their findings. If they agree, pass three's work is immediately discarded. If they disagree, the work it has already done counts toward the final findings.
From pass three onward, the moment a pass finds something the supervisor has not seen before, the next pass launches without waiting for the current one to finish. A pass that produces no net-new findings simply does not get a successor. This mechanism allows the loop to converge economically, triggering more passes when there is more to find and fewer when the diff is already exhausted.
This review loop is augmented by the Verifier, a separate long-running model conversation that consumes findings as they merge and acts as a final filter. The verifier catches the self-contradiction and hallucination that plagued our early single-pass approach. For instance, it checks that all symbols cited in a finding are actually present in the provided context, greatly reducing the risk of a finding being posted based on a model hallucination.
In aggregate, this loop produces reviews that are more thorough than a single pass and more consistent across runs than any single model call could be. It costs more compute, but the agreement gate kills most of the speculative work that doesn't pay off, and the convergence rule keeps successor passes from running on diffs that are already exhausted.
From Zero to 90% in One Quarter
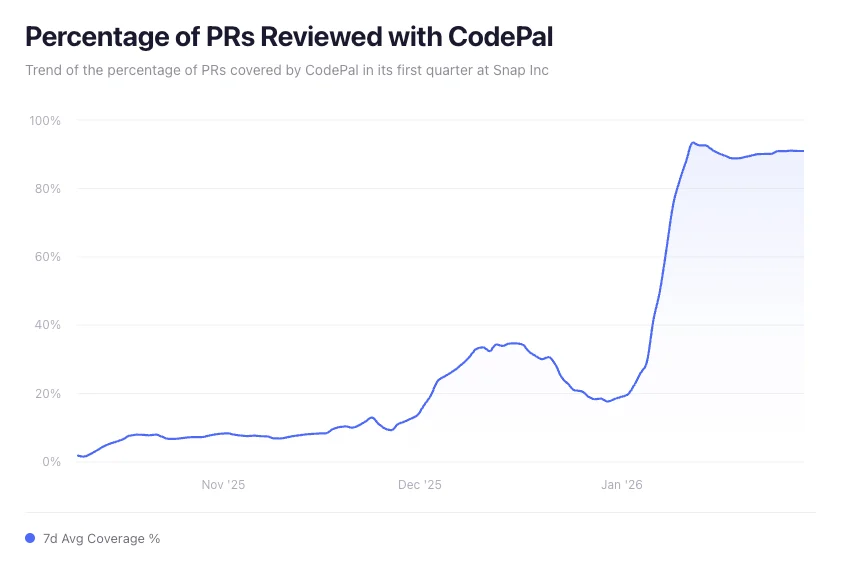
CodePal launched as an opt-in experiment, analyzing PRs for potential bugs and security vulnerabilities. Adoption began cautiously at 9% of PRs, but quickly grew as we made reviews mandatory in a handful of repositories, where consistent, thorough reviews were essential. As repository owners started opting in, CodePal was being used voluntarily across 300 repositories with >70% positive sentiment. After seeing bugs slip through that CodePal would have caught, engineers began asking for it to be the default. When we started to auto opt-in teams, the key takeaway was this: people weren’t asking us to turn it back off, they actually wanted it on. Within a single quarter, we went from virtually no AI-reviewed PRs to over 90% of all PRs at Snap having a CodePal review. Importantly, quality kept pace with adoption. During that same quarter, our recall rate climbed from 30% to 80%, and engineer sentiment on bug findings reached 80% positive.
Measuring Quality
Getting to 90% adoption was the first milestone, but adoption alone doesn't make a tool trustworthy; it makes the tool visible, and visibility exposes the cracks.
Three flaws stood out: reviews were inconsistent across runs, CodePal would sometimes hallucinate intent by assuming the wrong thing about what the code was supposed to do, and we had no process to validate changes before they rolled out. We relied on user feedback, which was too slow.
We built an evaluation framework so we could clearly understand where we were doing well, where we were doing poorly, as well as a process to AB test all new CodePal changes. We formed a ground truth dataset from real engineer feedback and set goals to improve the recall of true positives (real bugs that are able to be found consistently across reviews) and minimizing the false positives (only surface real bugs). Speed and cost stayed as guardrails, but the primary objective was trust.
Four investments drove the recall improvements:
Deeper code understanding: CodePal now uses cross-file symbol resolution and expanded language parsing, so it understands intent rather than guesses it.
The multi-pass review loop, described in The Review Loop section above.
Broader detection scope: The scope expanded from 8 bug categories to 12.
Incremental reviews: Each new commit triggers a focused re-review with auto-resolution of findings whose files have left the diff.
The impact of this work has been very promising. Our recall rate of true positives has increased from 30% to 80%, the rate of false positives in our golden dataset has dropped to 0% (measured on the held-out golden dataset, not on live traffic) and we're also finding 75% more bugs now with a positive rating than we were previously, with user sentiment sitting at 80% positive.
Building Trust in Each Finding
Quality metrics tell us the system is improving in aggregate. But every individual finding posted on a PR also has to earn its place, engineers won't tolerate noise from a reviewer they're forced to take seriously. Two mechanisms keep individual findings honest: a verifier that audits each finding before it's posted, and a feedback loop that turns engineer reactions into ground truth. Together, they form a system that gets more trustworthy the more engineers use it.
The Verifier, introduced in The Review Loop section, performs a final integrity check on each finding before it's posted. It runs alongside the review passes, consuming findings as they merge and auditing each one against the supplied context. For example, it checks that every symbol cited in a finding is actually present in the provided context. A finding that names a function the model didn't actually see gets dropped before it reaches the reviewer, preventing the self-contradiction and hallucination that plagued our early single-pass approach.
The reliability of our system rests on a strong feedback loop, which we call the Finding Lifecycle. When an engineer uses the thumbs up/thumbs down reaction on a CodePal comment, this signal is immediately recorded. A positive signal confirms a true positive, and a negative signal confirms a false positive. This live user feedback, along with findings that are merged without being addressed (i.e., ignored) and findings that are fixed by the author, is aggregated into our ground truth dataset, which connects back to our AB-test framework.
This is the engine of the evaluation framework. Every finding that gets posted, dismissed, fixed, or ignored becomes a signal for the next round of changes.

What We've Learned
After scaling CodePal across Snap, a few key lessons stand out.
Context over top tier model: We’re constantly testing which model best balances review quality, cost, and speed. However, in almost all cases where a missed bug was reported to us, the bigger issue was with the context supplied to the model. Frontier models these days are smart enough to catch almost anything as long as they have the information to know that it's a bug. At the same time, you don't want to overwhelm the model, which is a primary reason we chunk the review into logical parts.
Out of the box, it's surprisingly generalizable. For most repositories, CodePal provides high-quality reviews with zero configuration. The combination of a strong base model, the code diff, and symbolic context is enough to catch real bugs and provide useful feedback across languages and frameworks.
But the largest, most complex repos need more. In Snap's biggest repositories, which include hundreds of contributors, intricate internal libraries, and years of accumulated conventions, generic reviews start generating noise. This is where the customization layer becomes essential. Teams that invest in .codepal.yaml configuration and per-path instructions see dramatically better results.
Feedback loops matter. Engineers can vote on every CodePal comment with thumbs up or thumbs down. This feedback is recorded and influences future reviews. It creates a flywheel: the more engineers engage with CodePal, the better it understands what matters to them.
AI review doesn't yet replace human review, it reshapes it. The most common response we hear from engineers is that CodePal frees them to focus on the things that actually require human judgment: architecture, long-term maintainability, product implications. The system helps identify many routine issues before human review begins, allowing engineers to focus on higher-level design and judgment.
The Numbers
CodePal performed >200k reviews across 90% of all PRs over the last 4 months, catching thousands of confirmed issues that were corrected before human review and before reaching production.
CodePal reviews complete within 10 minutes while the median time to wait for the first human review is ~5 hours. This gives PR authors a near immediate feedback loop for them to iterate more quickly.
Adoption went from 0% to 90% of PRs within a single quarter.
80% positive sentiment rating from engineers on bug findings.
Reviews cost on average ~$0.40 per review.
The Bigger Picture
CodePal is one piece of a larger bet: that within the next few years the majority of PRs at Snap will be automatically written, reviewed, and approved by trusted AI systems, with humans focused on the decisions that require judgment, taste, or accountability. Today, CodePal reviews code written by humans and AI alike, but every PR still requires a final engineering approval. The path from "trusted reviewer" to "trusted approver" is what the rest of this series is about. In Part 2, we discuss how we built a semantic code search in order to make code easily discoverable and readable by both humans and agents. We then integrated code search into CodePal in order to expand our AI code reviews and look at changes downstream, even when they live in a different repo.
If you'd like to work on systems like this, we're hiring - apply here.