
Machine Learning for Snapchat Ad Ranking
Snapchat ad ranking aims to serve the right ad to the right user at the right time. These are selected from millions of ads in our inventory at any time. We do so with a strong emphasis on maintaining an excellent user experience and upholding Snap’s strong privacy principles and security standards, including honoring user privacy choices. Serving the right ad, in turn, generates value for our community of advertisers and Snapchatters. Under the hood, a very high throughput real-time ad auction is powered by large-scale distributed engineering systems and state of the art deep learning ML models.
This post details an overview of the Snapchat ad ranking system, the challenges unique to the online ad ecosystem, and the corresponding machine learning (ML) development cycle.
Snapchat ad ranking aims to serve the right ad to the right user at the right time. These are selected from millions of ads in our inventory at any time. We do so with a strong emphasis on maintaining an excellent user experience and upholding Snap’s strong privacy principles and security standards, including honoring user privacy choices. Serving the right ad, in turn, generates value for our community of advertisers and Snapchatters. Under the hood, a very high throughput real-time ad auction is powered by large-scale distributed engineering systems and state of the art deep learning ML models.
This post details an overview of the Snapchat ad ranking system, the challenges unique to the online ad ecosystem, and the corresponding machine learning (ML) development cycle.
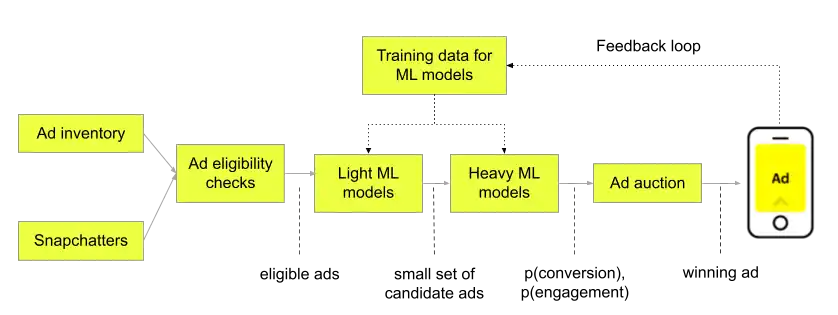
The process of determining which ad to show to the Snapchatter consists of multiple steps:
Ad eligibility filtering: As the first stage, we perform ad targeting, budget checks and other filtering steps, including privacy and ads policy compliance. This determines which ads are eligible for a given Snapchatter out of the entire collection of ad inventory.
Candidate generation: lightweight ML models then cull a smaller set of candidate ads (typically hundreds to a few thousand). The goal here is to maximize the recall for the next stage heavy ML models.
Heavy ML models: for each candidate ad, these models generate scores such as the probability of conversion after seeing an ad and the estimated organic utility of the ad.
Auction: finally, the scores from the ML models, advertisers’ bids for the ads, remaining budgets for the ads, and various business rules are used to run an auction that generates the final value for each ad and selects the highest value ad. This winner ad is then shown to the Snapchatter.
Feedback loop: interactions with the ad in turn generate training data for the ML models.
The ad marketplace dynamics presents some unique challenges to the ML system:
Scale, cost and latency constraints: our ML models operate at a very large scale; every day we make trillions of predictions using models trained on billions of examples. Such a large scale implies significant training and inference costs. These models also operate under strict latency constraints. A combination of highly optimized training platform, inference platform, and model architectures is needed to keep the cost and latency within acceptable limits.
Auction induced selection bias: the ad ranking ML models are trained on the engagement data from ads shown to Snapchatters. These are the ads that won real-time auctions. However, the trained ML models are used to make predictions on each candidate ad. As a result, if a model makes mistakes on candidate ads, the auction stage will pick the ad with an outlier score instead of the most relevant ad.
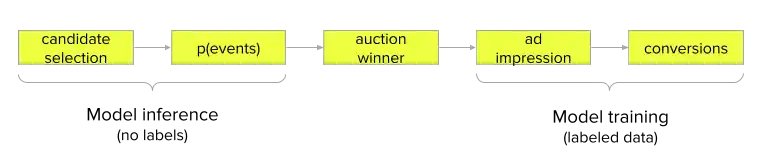
Calibrated predictions: the Snapchat ad platform bills advertisers on a per ad impressions basis while the advertiser might be bidding for a different conversion event such as swipe-up or app install. An essential requirement then is calibrated predictions: the total number of conversions predicted by the model should be close to the total number of true conversions on all major business segments. This is different from the typical recommendation or search ranking problems where the model predicted scores are used only to determine the relative ranking of documents or products; for ad marketplace, we do care about calibrated scores.
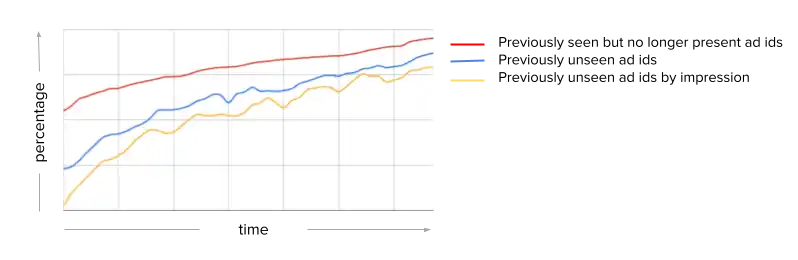
Fast-changing ad inventory: the ad inventory keeps changing rapidly as advertisers start new ad campaigns or stop old ones. This, in turn makes, it difficult to learn high-quality representations (embedding vectors) for various discrete features. At Snap, we have found that keeping the model up-to-date with new ad identifiers (ad-ids) in the system is critical. A model trained to support a fixed set of ad-ids will find that most of those ad-ids are no longer receiving traffic after several days and that the fraction of out-of-vocabulary (“previously unseen”) ad-ids becomes the dominant case.
Delayed and repeated conversions: the Snapchat ads platform allows advertisers to bid for various lower-funnel conversion events, such as purchasing after installing an app. The app-install or app-purchase event can take place up to a few weeks after the ad is shown to the Snapchatter; app-purchases can also happen more than once. This implies that the high-quality training data is available only after a long delay (a few days to weeks); however, the ML model trained on this delayed data would be stale and might not perform well on new ad campaigns.
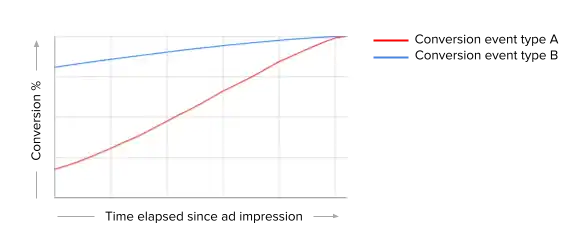
The chart above shows the gradual and steady increase of conversions reported for all ad impressions delivered on a single day. Hence, we are constantly facing this engineering tradeoff:
We can wait until the curves become “flat” to gain more confidence about our conversion labels, but this introduces more delay to our model updating.
We can also update our models with a shorter delay, but we risk having more false-negative labels because some positive labels may not have been reported yet.
The ML specific development goes through many logical steps such as offline experimentation, benchmarking and deployment for online inference, online A/B testing, continuous updates of models and performance monitoring. These are enabled by custom platforms and supporting infrastructure.
Ad features and signals focus on mining, extracting, curating and modeling signals from different data sources to power ad ranking machine learning models.
We process signals collected from various channels and product surfaces. The logical and semantic structures behind these data are complicated, and they can’t be directly fed into the ranking model training pipeline. To address this, we have built appropriate data models and featurization technology. On ads understanding, we are also tackling the industry level challenge of bridging the gap between content modeling systems and recommender systems. We apply recent ML breakthroughs from NLP and CV to the ad ranking models to deliver more personalized ads, even with sparse prior engagement data.
Two main challenges cause high friction in feature engineering:
New features are added first for logging to avoid offline-online skew (forward filled). ML engineers have to wait for a few weeks for data to accumulate before they can train any model using new features.
Adding new features require code changes in the feature generating pipeline, case by case testing and deployment.
To address these, we built an in-house platform that allows adding simple features and their statistics through a declarative config and automates the end-to-end flow from feature generation to pushing data to the online serving system. This allows for quick offline feature experimentation without waiting for the forward fill and unifies various feature pipelines.
Ad ranking ML engineers aim to improve the prediction quality and cost-efficiency of ML models on an ongoing basis. Examples of such innovations include highly customized deep learning architectures, better problem formulation and optimization techniques (e.g., handling delayed conversions), hyperparameter tuning, data sampling for efficient training, and models that make efficient use of the underlying hardware. We train models with hundreds of millions of parameters using billions of rows of ad impression data. Each row of training data contains features about the ad/user/context and post-impression actions (“labels”) that the Snapchatter took after seeing the ad.
We make use of current state of the art multi-task models such as MMoE [6] and PLE[7] to predict multiple conversion events jointly (e.g., app installs, purchases and sign-ups). Our models also use the latest high order feature interaction layers such as DCN [3] and DCN v2 [8] as a building block. We further optimize these models for inference cost and latency by splitting them into multiple towers, e.g., one for processing user features and the other for ad features. We demonstrate these components and connections among them with the figure below.
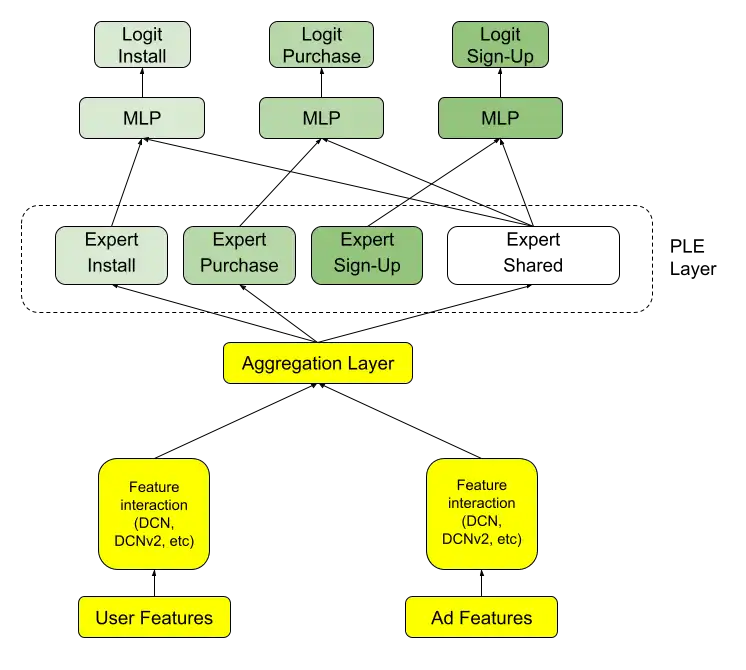
Both the relative ordering of ads as well as the raw conversion probabilities are used in the ad auction; consequently, we typically use the Normalized Cross Entropy (“NCE”, [1]) as our primary offline metric for experimentation; we also use AUC and calibration as secondary metrics to diagnose the ML model behavior. Metrics are computed on future data, e.g., the NCE on the seven days of impressions after the training date range. Models that demonstrate a significant improvement in future NCE are registered for continuous updates, put online for A/B testing, and (eventually) rolled out fully.
Distributed training
Building and improving deep learning models require a large number of offline experiments. Fast training, low training cost and a reliable platform that can process these long-running jobs with a minimal failure rate are required to ensure the highest experimentation velocity for the team.
Training models on billions of rows of data while meeting speed, cost and reliability considerations is challenging. We have built an efficient and scalable distributed system to address these. We primarily rely on data parallelism techniques with asynchronous gradient updates to maximize speed. Our training system is fully managed and requires little effort from ML engineers to start training at scale from a few dozen to hundreds of machines.
We recently started to migrate training to Google’s TPU technology. Over time, ad ranking models kept getting larger and larger, so it was critical to use specialized hardware to keep a reasonable training time. TPU’s high compute throughput, interconnect bandwidth, and convenient integration with TensorFlow make it well suited for our recommendation systems’ numerous large embedding matrices. We observed a more than two-thirds reduction in training cost due to significantly shortened training times and competitive prices per unit training time for TPUs.
Continuous update of ML models
Ad ranking ML models benefit from frequently updating them to make use of the most recent training labels [1]. This allows the ML models to adapt to external changes quickly.
Training the ML model from scratch every time new training data arrives is infeasible; the training cost and time would be prohibitive. The most common strategy is warm starting from a recent checkpoint of a previously trained model, periodically (hourly to daily) batch update it on new training data using some flavor of stochastic gradient descent (SGD) optimization algorithm and saving this checkpoint for future iterations.
ML model calibration
The models trained with binary cross-entropy loss have theoretical guarantees on calibration on the training data. This, however, is usually not sufficient to ensure a well-calibrated model in production: the calibration guarantees do not apply to unseen future data with possibly different data distribution than that seen during training; the model might have been trained using a custom loss function such as an auxiliary loss or a multitask learning loss; and the auction winner selection effectively acts as picking up an outlier score and results in over-calibrated models when put online.
We apply an automated calibration correction layer on top of the existing ad ranking ML models to ensure that the expected number of conversions predicted by the model stays close to the realized conversions. This layer is usually a simple ML model (e.g., Platt scaling, isotonic regression, or a simple neural network), which takes the predicted scores from ad ranking ML models as one of the features. The final corrected calibration loss must stay below a threshold; we treat this as a constraint metric during the A/B testing.
Workflow management and model deployment
ML engineers use an in-house platform for the training and management of models. The platform provides a declarative interface for users to express their experiments' fundamental properties, including data specification, model architecture, training loop, evaluation metrics, etc. Primary use-cases are served via a code-free YAML based config spec. The spec is translated into a workflow, a DAG of standardized tasks, and submitted for execution. The standardized task typically maps to a single atomic and idempotent cloud job. Users can create new tasks for advanced use-cases and submit the resulting workflow along with their custom task code packaged as a docker image.
Models that are found to be promising in their initial metrics are handed off to the platform to manage via automated updates. The platform automatically generates and evaluates a sequence of model checkpoints using newly arriving batches of data (selected using the original data spec) at a pre-defined cadence. Models that are found to beat the baseline on relevant metrics over successive checkpoints consistently are exported to the inference system to be deployed online for a/b test. The training platform continues to manage the automated incremental model and calibration updates for these models. Appropriate on-call alerts are also set if the model fails to update in time or its scores drift significantly.
Our workflow implementation is based on Kubeflow pipelines with in-house proprietary extensions. Users interact with our training platform via client APIs or the web UI. Multiple watch dogs work in the background to track execution status and resource consumption cost. The inference benchmarking suite enables an engineer to understand the model's performance and cost profile before deploying the change online.
Online budget split A/B testing
Estimating the business impact of any change by first exposing only a small set of randomly chosen Snapchatters to that change (aka, A/B testing) is a common practice for internet companies. This provides a framework for risk mitigation, data-driven decision making and learning by experiments.
Snapchat ad auction is a two-sided marketplace with advertisers on one side and Snapchatters on the other side. Running A/B tests in a two-sided marketplace is highly nuanced [9]. For example, exposing a set of Snapchatters to a new ML model can consume a nontrivial part of advertisers’ daily budgets which in turn cannibalizes the budgets and ad impressions available to the other models. These interactions introduce bias in measurement. We address this through a budget-split testing framework: each advertiser’s budget is split into N parts, each Snapchatter is randomly assigned to one of these N splits, and a change is applied only to one of the N splits (a similar budget-split design is described in [10]).
Online monitoring of features and ML models
Ad ranking ML models make trillions of predictions every day and drive billions of dollars in advertiser spend. These predictions directly and immediately impact what ads are shown to Snapchatters and how much the advertisers pay for displaying those ads. Any mistake can have a massive cost in addition to eroding advertisers’ confidence in Snap’s advertising platform.
Model predictions can go off the rails because of some broken input features to the model, some numerical instability, or some operational issues. At the very least, a set of checks and tools are needed to identify in real-time what caused a production incident in an ML system. This is usually achieved through real-time feature monitoring and ML model score monitoring systems.
Our feature monitoring system can deal with challenges such as thousands of features owned by multiple teams with different platforms and update cadence; different types of features: numerical (scalers, fixed dim vectors), high cardinality categorical, high cardinality variable-length list of categorial features; and monitoring features that are present only for a small segment of traffic or only for a specific model type. Similarly, our ML score monitoring system can deal with challenges such as hundreds of ML models, each going through multiple updates every day; high churn of models (stop old experiments, start new ones); and external changes that can affect score distributions. These monitoring systems strive to have a short time to detect (typically a few minutes), a high detection rate for an incident and a low false-positive rate.
Ad ranking for Snapchat provides the right scale and business impact potential to continuously develop and apply state of the art ML algorithms and infrastructure. Through this article, we intend to share an overview of our ad-marketplace, the role ML plays in ad ranking, the challenges unique to ML for ad ranking, and various components of the end-to-end ML development cycle.