Modernizing the PlayCanvas Backend Infrastructure
PlayCanvas is the leading HTML5 game engine powering 3D experiences and games on many of the world’s most popular websites. PlayCanvas joined Snap in 2017 to help build Snap Games, Snapchat’s multiplayer gaming platform. Today, more than 80% of Snap Games developers have opted to use the PlayCanvas cloud-based platform to build their games. And over 200M Snapchatters have now played these PlayCanvas-powered games.
Over the past 2 years, we have upgraded the PlayCanvas backend to be more scalable, observable, and reliable. In this article, we will cover how, during those years, the application of modern approaches, technologies, and design patterns helped us to resolve the problems we faced.
PlayCanvas is the leading HTML5 game engine powering 3D experiences and games on many of the world’s most popular websites. PlayCanvas joined Snap in 2017 to help build Snap Games, Snapchat’s multiplayer gaming platform. Today, more than 80% of Snap Games developers have opted to use the PlayCanvas cloud-based platform to build their games. And over 200M Snapchatters have now played these PlayCanvas-powered games.
Over the past 2 years, we have upgraded the PlayCanvas backend to be more scalable, observable, and reliable. Here, we’ll detail how we’ve evolved it, and detail some of the new approaches we took to overcome technical hurdles.
PlayCanvas originally consisted of 62 backend pipeline jobs and 13 services running on a fixed number of AWS EC2 instances. We used Nginx as a reverse proxy for public-facing services and Supervisor to keep services running on servers. Most services and jobs used Node.js, but we also had some services written in Python. DataDog was used for CPU/Memory metrics and Stackdriver for logging.
The PlayCanvas community grew substantially in recent years and we started to experience problems with scalability. Some services were running at their limit almost daily, reporting more than 80% CPU usage. For example, the texture compression service would sometimes take over an hour to process a batch of textures. Unfortunately, we couldn't easily scale it up because setting up the service on a new instance was a manual process. We also received customer reports about slow services or services occasionally going down. It was not easy to find the cause. The only way to debug was by logging, and we sometimes could not find any errors in the logs related to this problem.
It was clear that we urgently needed to improve our infrastructure to stabilize resource usage, improve observability and scalability and eliminate outages.
At the time, we had a number of manual processes (e.g. deploying an Nginx configuration update), leading to short periods of downtime. Scaling would involve launching AWS EC2 instances manually, installing all the necessary middleware like Node.js, Supervisor, Nginx and linking the instances to LoadBalancer. Security requirements dictate that we update server instances regularly which was an arduous manual process and unfortunately, any manual process is susceptible to human error. Also, as a team, we are always looking to optimize our efficiency, so wasting time on manual processes was definitely something we wanted to avoid.
We needed a more systematic approach, allowing us to deploy everything automatically, thereby reducing the possibility for human error. We wanted to use an auto-scaler and apply the same principles everywhere, while being compliant with the security requirements.
We had several potential solutions for scaling. Either using AWS EC2 AutoScaling or using container-based solutions (e.g. Docker Swarm or Kubernetes), or even jumping to serverless land and using lambda functions.
AWS EC2 Auto-Scaling would be the simplest solution, but it wouldn’t solve everything. We still needed to automate deployment and solve other problems, like manual Nginx configuration updates and manual software upgrades. The serverless approach is ‘trendy’ and could solve our scalability problem, but it was too far from the current state of the backend at the time and would take much longer to implement.
Containerization looked like an ideal solution for deployment automation. Using containers would simplify deployment, as we could describe all dependencies in code (Dockerfiles) and package services with all dependencies into a deployable unit. To deploy containers over a set of servers, we needed some container orchestration solutions.
Several options were available as noted above: Docker Swarm, Kubernetes, plus some others. Docker Swarm seemed easier to start working with, but Kubernetes looked like the perfect candidate as the industry standard for deploying and scaling software in containers, and it also allowed us to better align with Snap infrastructure. The rest of Snap is transitioning to a multi-cloud Service Mesh architecture based on Kubernetes. Being able to deploy our backend on the Snap infrastructure in the future was also an important goal. Having more people familiar with a technology is also an important factor when hiring.
Kubernetes is an open-source container orchestration system for automating software deployment, scaling and management. It simplifies and automates a lot of tasks related to software deployment and provides a relatively simple command line interface. According to the 2021 Cloud Native Survey, the usage of Kubernetes is continuing to grow worldwide and reached its highest level ever, with 96% of organizations using or evaluating the technology. We already used Amazon Web Services (AWS EC2) for our infrastructure, and the team had the most experience with Amazon services, so AWS Elastic Kubernetes Service (EKS) was a natural choice for our future Kubernetes cluster.
Using Kubernetes would help us to completely automate deployment and eliminate all manual processes, so we could easily re-deploy all services on more powerful machines or scale them horizontally. It would also allow us to use a unified approach for everything, using the same relatively simple API for debugging, logging and other tasks.
Another important goal was avoiding downtime during the upgrade process - we didn’t want to affect people using our platform every day. To solve this, we selected an incremental approach to upgrade, containerising our services and jobs one by one, and carefully routing traffic to new services while being able to quickly rollback if something was to go wrong.
To improve observability, we needed to integrate error-tracking software, report detailed service metrics and improve our logging subsystem.
After several discussions, we decided to move our infrastructure to a Kubernetes cluster on AWS infrastructure to improve scalability and reliability.
In the next sections, we will explore how we further decided to:
Improve observability and debuggability by deploying a new metrics system and Sentry as an error monitoring system.
Introduce a CDN to reduce latency in remote regions.
Before implementing the changes described above, we needed to understand any bottlenecks and measure the potential impact of moving to a new infrastructure. After considering several alternatives (such as DataDog), we selected Snap’s internal Graphite-based stack for a metrics backend and Grafana for a frontend to implement a set of metrics and dashboards to monitor every service and job. We integrated detailed requests, availability, CPU/Memory statistics and other metrics and built corresponding dashboards (with automated generation) for detailed service monitoring.
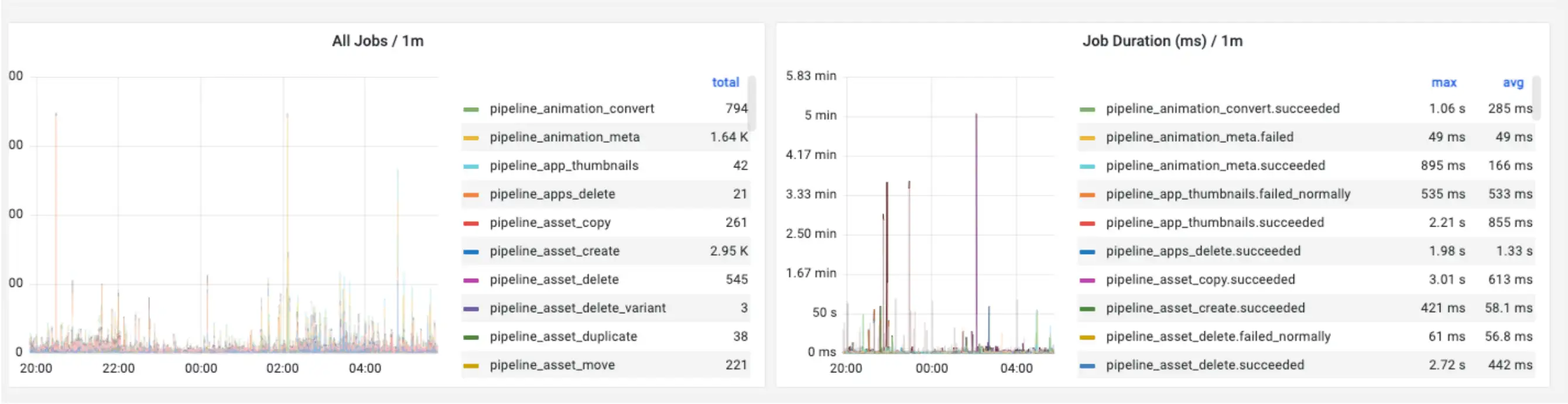
We built a ‘Platform Overview’ dashboard where all the important metrics were collected on a single page to quickly communicate the state of the backend at any time. This included detailed dashboards for every service.
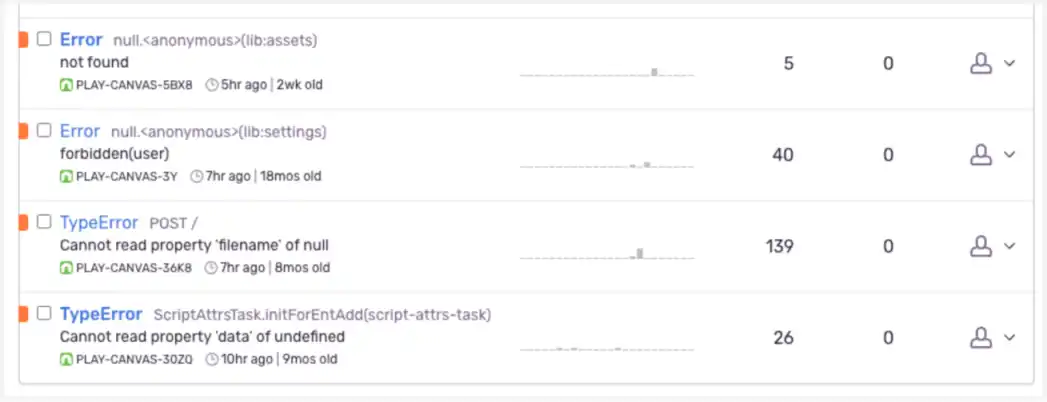
Being able to quickly react to any issue with a backend is very important. Sentry is an open source software that helps to monitor crashes and issues in real time. By introducing Sentry, we were able to significantly reduce the time to resolve issues as well as find and fix some very tricky bugs. Integrating with Sentry was also relatively easy because it has all the necessary libraries for almost every language. With Sentry, we can immediately respond to any errors by setting up alerts and email notifications, while still seeing all the information needed to resolve the issue: call stack, console output, affected service, etc.
We also unified logging by sending all logs from jobs and services to AWS CloudWatch. Containers are ephemeral, so logs need to be uploaded somewhere. We selected AWS CloudWatch because it is a part of the AWS ecosystem and simple to integrate. AWS CloudWatch has Logs Insights, a tool to search information in logs with a convenient query language.
Having detailed metrics and Sentry in-place, we were ready to containerize our services. The first thing we had to do was create a Kubernetes cluster. We followed the ‘Infrastructure As Code’ methodology and coded a cluster with all necessary setup in AWS CloudFormation templates. This enabled us to automatically re-create infrastructure as required.
We began with our pipeline jobs since this was the simplest way to start - they are not public facing. Pipeline jobs are small services created to serve a single purpose, like uploading an asset or publishing a project. PlayCanvas has more than 60 jobs, so this took a considerable amount of time. We selected Alpine images as base container images because of its small size, which allowed us to make final container images as small as 200Mb.
The next thing to containerize were public-facing services, such as the Editor and the playcanvas.com website. They were containerized over the course of a few months, one by one. We also replaced Nginx with Nginx Controller for Kubernetes and automated its deployment. Nginx Controller is a useful piece of software, automating configuration deployment and LoadBalancer creation and serving as an entry point for traffic to the cluster.
Using Kubernetes allowed us to introduce zero-downtime deployment. It works by stopping an old version of a service and simultaneously starting a new one. The old version of a service stops accepting new traffic and continues to process existing requests until it drains completely. After that, it’s finally terminated.
We planned one more improvement: introducing a Content Delivery Network (CDN). It is a service offered by Cloud Providers to deliver bulky files worldwide. It works by caching files at edge locations using powerful servers deployed to every world region. As we were already on AWS, the natural choice was Amazon’s CloudFront service. CloudFront uses the AWS network backbone: fully redundant, multiple 100GbE parallel fiber that circles the globe and links with tens of thousands of networks.
By simply deploying AWS CloudFront in front of our backend, we were able to reduce latency in every world region by 50%. By using CloudFront instead of AWS S3 for delivering project downloads, we improved download speed for huge projects between 10 and 30 times in Asia.
Having a CDN also allowed us to carefully containerize services, one by one, without downtime and quickly switch between containerized and non-containerized versions.
Introducing a CDN led us to another improvement: Asset Delivery with CDN. For PlayCanvas, assets are 3D models, textures and other resources used by 3D games or applications. We had a tricky issue with asset requests, where some requests were failing with a “socket timeout message”. Thanks to Sentry we had a callstack, but it wasn’t easy to understand the real cause. After a deep dive, we found out that our internal logic to stream assets from S3 directly wasn't scalable enough. The decision we made was leveraging AWS CloudFront (CDN) to stream assets, with permissions checks implemented using Lamda@Edge - a serverless function running on edge locations closer to customers. Switching to this new system resulted in up to a 50% improvement in project loading time. Assets are now cached on edge locations across the world closer to customers, which helps with regionalization.
After containerizing the entire backend, introducing CDN, Sentry and detailed metrics, the PlayCanvas backend became more reliable, observable and scalable. The next phase for us will be to improve our CI/CD pipeline and leverage CDN further still.
Are you interested in technical challenges such as these? The PlayCanvas team is looking for a talented Full Stack Software Engineer. If that is not a great fit for you, try browsing all openings listed on Snap’s Careers Page.