Inside Snap's Experimentation Platform: Leveraging NVIDIA GPUs for Accelerated Data Processing
Migrating Snapchat’s AB Pipelines to GPU-Accelerated Spark
At Snap, experimentation sits at the core of how we build products. Nearly every product decision is informed by controlled experiments, and the infrastructure that powers those experiments needs to be reliable, scalable, and fast. As Snapchat has grown, so has the scale of experimentation, and with it, the cost and complexity of the data pipelines that support it.
At the same time, GPU acceleration for batch processing workloads had matured significantly. Apache Spark accelerated by NVIDIA cuDF promised substantial speedups for shuffle-heavy workloads, the exact profile of many of our Spark jobs. The question was no longer whether GPUs could help, but whether they could help our pipelines at our scale, without compromising reliability or increasing operational complexity.
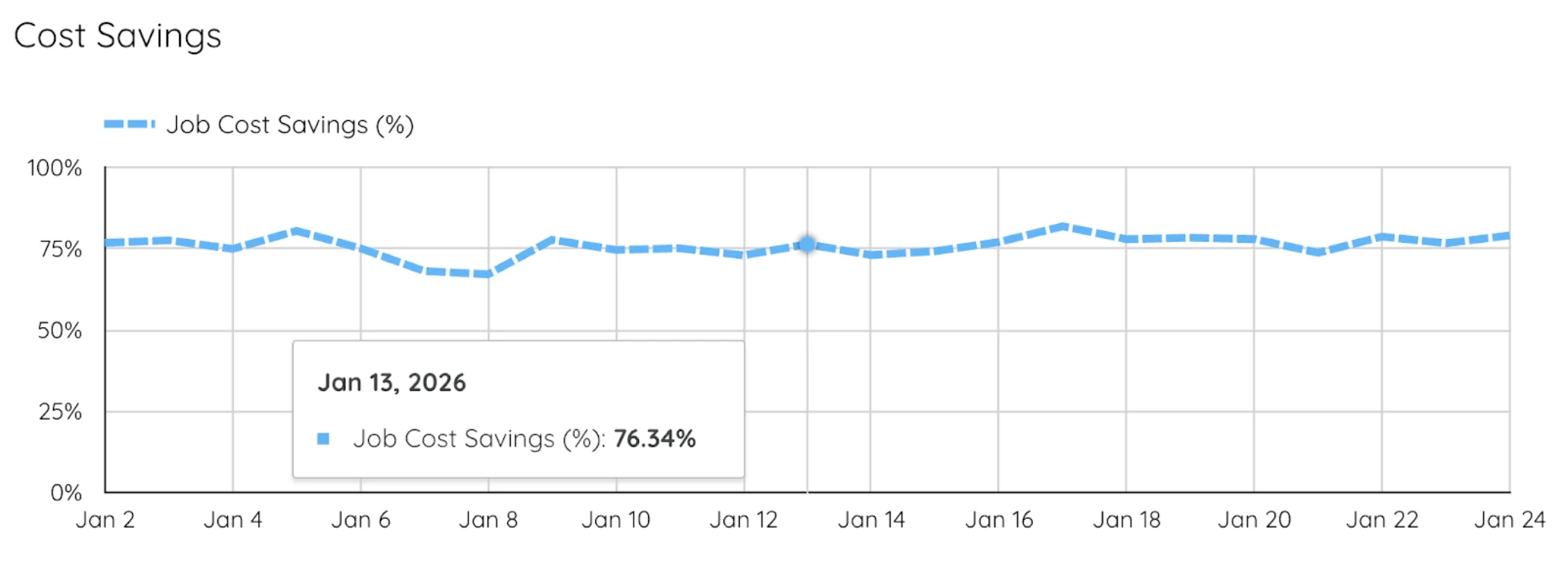
This post details our journey of optimizing large-scale spark execution with NVIDIA GPUs on Google Cloud. We migrated some of our largest Spark pipelines to GPU-accelerated execution, and saw over 76% in cost savings 1. We’ll cover what worked, what didn’t, and how shared GPU infrastructure unlocked both significant cost savings and a more sustainable path forward.
The AB Pipeline at Snap: Scale, Cost, and Constraints
The experimentation data pipeline is a collection of PySpark workloads that compute and aggregate the results of controlled experiments across Snapchat. These workloads power our internal experimentation dashboard, the AB Console: the primary interface engineers and data scientists use to configure studies, monitor performance, and analyze results. Today, this system supports more than 1,600 unique users, backs over 1,200 active studies at any given point, and exposes more than 6,000 metrics used to evaluate product changes 2. These metrics span a wide range of advanced statistical methodologies, including variance reduction (CUPED), heterogeneous treatment effect detection, and sample ratio mismatch diagnostics, ensuring that results are not just fast, but statistically rigorous.
From a data perspective, the pipeline produces both hourly and daily results. Hourly pipelines exist to provide quicker turnaround time for analysis, while the daily batch workloads compute the authoritative results for each study. These daily jobs run under a strict morning SLA, with all workloads executing between roughly 3 AM and 6 AM, ensuring results are ready for consumption early in the day.
Overall, the AB pipeline works on a massive scale: 10+ PB processed daily, mostly just within that three hour window 3. For the purpose of this migration, we first wanted to attack just one of the ten sub-pipelines, “Daily Sum”, which works primarily to generate engagement metrics for experiments configured in the console.
Original Pipeline Configuration 4
Primary pipeline
Daily Sum
Number of shards
38
Machines per shard
1,200 e2-highmem-8 (non-preemptible)
Google Cloud Platform Region
us-central1
Overall machine footprint
~45,000 machines
The pipeline needed to be highly reliable, able to scale horizontally across many shards, strictly bound to its SLA window, and cost-efficient enough to grow with experimentation demand. Any optimization that meaningfully reduced cost or runtime would have an outsized impact, but failures or instability were not acceptable.
Exploring GPUs for Spark: Initial Experiments
Our initial exploration focused on running Spark on GPUs using NVIDIA’s RAPIDS Accelerator for Apache Spark on Google Cloud Platform’s Dataproc. At a high level, the accelerator replaces CPU-based Spark operators with GPU-accelerated equivalents, providing the largest gains for workloads dominated by joins, shuffles, and repartitions.
Early testing confirmed this aligned well with our pipelines. Non I/O-bound jobs saw significant speedups, particularly in join and repartition stages. Direct aggregations such as sum() showed more modest improvements, as these operations were already relatively efficient on CPUs. Jobs that were bottlenecked on I/O saw fewer gains.
This led to several configuration learnings:
Worker-to-GPU balance matters: Through experimentation, we found that a balanced 1:1 worker-to-GPU ratio worked best across our mix of workloads.
GPU speedups are workload-dependent: Join and repartition-heavy stages benefited the most, while direct aggregations and I/O-bound stages saw smaller gains.
We ran a variety of benchmarks, including the Spark on GPU Benchmark suite, and observed speedups across essentially all job types. In practice, this translated to either a 1.5-3x as fast runtime with the same number of machines, or achieving the same runtime with 30-60% of the original cluster size 5.
Much of this benefit came from better memory utilization and drastically reduced spill when running on GPUs. These results gave us confidence that NVIDIA’s accelerator could work at our scale.
Google Dataproc on GPU
Our team initially looked toward managed Dataproc clusters equipped with GPUs for our processing needs. The release of the Dataproc 2.3 ML image, which included a pre-installed RAPIDS driver, was a significant development that reduced cluster creation times from generally ten minutes to five. Given our tight SLA constraints, this improvement was vital as it removed several manual initialization steps for the RAPIDS jar.
As an initial test, we transitioned a portion of our daily sum shards to GPUs:
While this migration significantly decreased the size of individual clusters, we encountered scaling challenges. At that time, our scale requirements necessitated a more strategic capacity approach.
Although Dataproc on GPU confirmed the performance improvements we anticipated, it also highlighted that on-demand capacity could not support our entire production footprint. The AB pipeline operates within a narrow morning window, creating a high concentration of GPU demand. Maintaining our SLA would require processing roughly seven shards every thirty minutes, necessitating approximately 2,100 concurrent L4 GPUs and a total of 11,400 L4 GPUs throughout the full execution 6. Since this requirement for burst capacity surpassed what was available, it became evident that we needed an alternative strategy for managing capacity.
The Turning Point: Inference Platform GPU Stack
The breakthrough came from Snap’s Inference Platform team. The team had created an infrastructure for the ML serving layer to leverage GPUs already, with a rather mature ecosystem of quota sharing and borrowing built out for their workloads. Importantly, it integrates with Prism, Snap’s central data processing platform, which simplifies job submission and provides a standardized execution layer for batch workloads. Working with their team, it became apparent that leveraging their same stack could be the key to running our pipeline in off-peak times to find the GPUs we needed.
The long-term vision was compelling: a platform where jobs could seamlessly run on GPUs when capacity was available, and automatically fall back to a CPU-based architecture otherwise. For the AB pipeline, this unlocked access to large amounts of stable GPU capacity without requiring additional infrastructure work.
There was, however, a catch. Or two.
New Challenges with GKE
The Inference Platform infrastructure for the serving layer logically supported Kubernetes clusters only, which meant that to use this capacity, we needed to migrate to Google Kubernetes Engine (GKE). Spark on Kubernetes has some important differences from Spark on a managed service like Dataproc.
Spark on GKE introduced several new constraints:
Reduced effective resources: Pod-level overhead meant executors had slightly less CPU and memory than raw machine specs suggested. An e2-standard-8 machine on GKE won’t be able to use all 8 cores as Spark CPUs, as some portion will be used for pod infra processes, meaning we’ll more likely be able to use something like spark.executor.cores = 7.
Loss of managed defaults: Dataproc provides many useful Spark configurations by default, many of which need to be replicated manually.
Per-job GPU allocation: While we previously submitted multiple jobs to a single Dataproc cluster, Spark on GKE via the Spark Operator required GPU resources to be requested on a per-job basis.
Subsequently, the infrastructure provided by the Inference Platform itself imposed additional constraints:
Custom GPU image required: We needed to develop and maintain our own GPU-enabled Spark image for GKE.
Fixed machine shape: This infra was strictly for g2-standard-48 machines, each equipped with four L4 GPUs, and did not support local SSDs. Compared to g2-standard-8, the GPU-to-core ratio was worse (1:12 instead of 1:8), meaning executors could take on more tasks but were more likely to hit memory pressure. The lack of local SSDs was particularly concerning for our shuffle-heavy workloads.
Finally, there was still the issue of timing; the off-peak time window was primarily between 12 AM and 6 AM. Prior to this migration, the AB pipeline typically ran between 6 AM and 9 AM, leaving us unable to leverage available machines!

Because of these concerns, we preferred to migrate with a fallback logic: if a workload failed on GKE, it could be re-attempted on the original Dataproc-based architecture.

Maintaining this safety net introduced additional complexity. And it was messy.
Complicated Airflow dependency stitching
Error-prone retry and fallback logic
Increased engineering overhead
Reduced confidence in making larger, riskier changes


Single shard in Airflow after fallback logic
Engineering the Solutions
Spark on GKE Tuning
Machine type
g2-standard-48
Total machine resources
48 vCPUs, 192 GB memory 7
Effective executor resources, after pod overhead
~11 cores, ~43 GB memory
Executors per job
1 executor per GPU
Parallel job streams
2
Original Dataproc on GPU estimate, cluster-mode
300 g2-standard-8 nodes
Final GPU mapping
75 g2-standard-48 nodes 8 , shared across 2 jobs
Also, for memory-intensive workloads, we traded some parallelism for stability by running executors with fewer cores, often 8 instead of 11, while keeping the same memory allocation. This was essentially an artifact of moving from highmem machine types to standard ones, the latter being offset a bit by the GPU reducing memory usage.
Developing the GPU image itself was straightforward but required extensive testing. With help from the NVIDIA team and their official guide, we built an image that:
Used CUDA as a base
Added Spark and required connectors (GCS, BigQuery)
Included the spark-rapids JAR and GPU discovery scripts
Installed our pipeline’s Python dependencies
Without access to local SSDs, we needed an alternative to avoid shuffle spill. Kubernetes supports PersistentVolumeClaims (PVCs) that can be attached at runtime, which turned out to be a perfect solution. Our jobs now request 400 GB pd-ssd volumes, closely matching the performance characteristics of the local SSDs we previously relied on.
NVIDIA’s Project Aether, an automated Spark tuning tool, played a key role throughout the migration. Given an event log, Project Aether produces recommended configurations for GPU execution, as well as suggestions to improve runtime or cost. It helps in multiple ways:
Indispensable for initial migration settings: the tool provides a sensible set of defaults that are necessary for the spark-rapids jar, as well as potential general Spark configurations that are quite useful.
Consistent tuning: the tool can be used on already-migrated jobs to improve performance even further.

Another internal initiative, codenamed Swift Insights, aimed to deliver earlier AB results. This work allowed our pipelines to shift into the 3 AM–6 AM window, aligning perfectly with the downtime in GPU usage.
Migration Timeline



Results: Reliability, Performance, and Cost
From an operational standpoint, the system has been stable. GPU job success rates typically fall between 96% and 98% day-over-day.

Fallback rates, where jobs revert to a CPU-based architecture, hover between 3% and 8%.

Peak GPU usage reaches roughly 2,100 L4 devices. 9

The cost impact has been substantial, as we see over 76% daily savings for the daily sum and hourly pipelines.

The above graph shows how our current cost is broken down; it’s made up of the following categories:
GPU Executors: Our g2-standard-48 machines, the vast majority of compute as the Spark executors are this machine type.
Driver / Fallback: The Spark drivers use CPU images and n2d-standard-16 machines, as do the fallback jobs when GPUs are not available.
PVC Storage: Storage in the form of PersistentVolumeClaims as opposed to local SSDs attached to the machines.
Dataproc Fallback: Dataproc machines used in case of CPU-based jobs failing as well.
We’re able to see such a large improvement in cost savings while retaining a similar overall runtime due to the core efficiency of these GPU-based machines in our jobs. The overall footprint of the daily sum DAG changed drastically:
Before
After
% Change
VMs
45,600 e2-highmem-8
2,850 g2-standard-48
-
Cores
364,800 10
136,800 7
-62.5%
Memory
2,918,400 GB 10
547,200 GB 7
-81.25%
GPUs
-
11,400 L4 GPUs 7
-
This migration validated that GPU acceleration for Spark is not only viable at large scale, but transformative when paired with shared infrastructure and the right platform abstractions. It demonstrated the value of treating GPUs as a shared, first-class resource for batch processing at Snap. For the AB team, it unlocked a path to sustainably scale experimentation without proportional increases in cost. The next steps are to onboard more of the AB pipeline to the same GPU based architecture using the mechanisms built out over the course of this primary migration (safe fallbacks, quota queue utilization, our generalized PySpark + GPU docker image).