
Embedding-based Retrieval with Two-Tower Models in Spotlight
At Snap, we want to empower you to learn about the world and have fun with other Snapchatters. On Spotlight, Snap’s short-video platform, we personalize what you see based on your interests and previous watch history. This blog discusses the challenges we faced and techniques we applied for large-scale embedding-based retrieval, which selects the stories that users may like from a large candidate pool in real time.
Spotlight is the short-form video product in the Snapchat app, where Snapchatters can watch entertaining content based on their interests and watch history.
To recommend the most relevant videos to Snapchat users, a naive approach would be to score all eligible videos for each user and choose the highest-rated ones. However, given the massive content pool and the scale we are operating with, this is obviously not only too expensive, but also unable to meet online serving latency requirements. What’s more, Spotlight videos have very limited text input, like the description and hashtags, from the creators, which makes it hard to employ traditional text-based information retrieval techniques.
In this blog, we will describe how we developed an embedding-based retrieval (EBR) system to solve these challenges and improve the performance of the Spotlight video recommendation system. The system has been playing an important role in the whole ranking pipeline to meet personalization and latency requirements at scale.
In representation learning, objects of interest are represented by dense vectors, also known as embeddings, in a latent space. The similarity between two objects' embeddings (such as cosine similarity) can be used to measure the relevance or similarity of the objects. In the context of Spotlight video recommendation, we can generate embeddings for viewers, creators and stories. In this blog, we will focus on the use of embeddings in the retrieval layer, although the generated embeddings can also be useful in ranking.
As shown in Figure 1, the Spotlight recommendation system consists of the retrieval part and the ranking part. The retrieval layer fetches ranking candidates from a diverse set of retrieval sources to maximize recall. The EBR sources have become more and more important in the whole retrieval stack. As we will share more details in the rest of the blog, we adopt the popular two-tower model structure to generate embeddings for Spotlight viewers and stories. Such model structure is both scalable and flexible to iterate on.
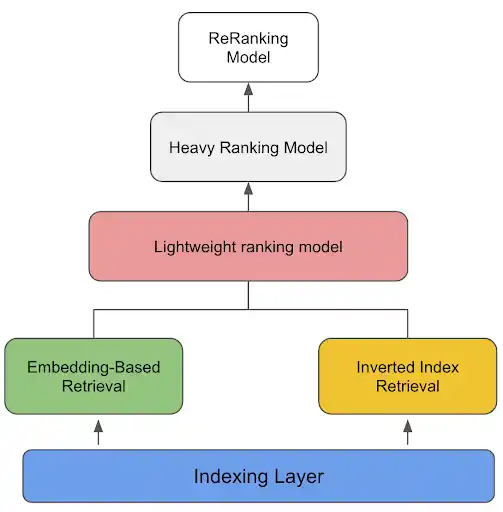
Figure 1. High-Level Overview of the Spotlight Recommendation System
The rest of this blog is organized into the following sections. We will first describe the two-tower model architecture and the features used in the model. Next, we will discuss the optimization strategies during the model training, which is followed by the embedding generation and inference for the two-tower model. After that, we will cover the online serving of the retrieval system. Finally, we will review our achievements and discuss future work.
The overall model structure is divided into three parts: the input layer, the representation layer, and the output layer.
Firstly, the input layer manages the data and features for the deep learning models. In two-tower models, user-story interaction logs are separated into user-related features and story-related features. The most important thing is that we should keep the features from each side independent from each other, since the embeddings generation should only include the information for just one type of entity. Both dense and sparse features were used in the model. For dense features, user demographic data and past engagement statistics are processed and transformed before fed into the models. For sparse features, we generate several sequence lists based on users' engagement in the past with average pooling techniques, which can bring a strong signal on user interests. Besides the user-side features, we also have story features, creator features, and the content embeddings with the collaboration with the content understanding team within the story tower. From a user privacy perspective, the two-tower models rank Spotlight stories via a user’s prior engagement with Spotlight. As such, both the training step and the inference step of the two-tower models do not allow users to learn about other people’s Spotlight interests
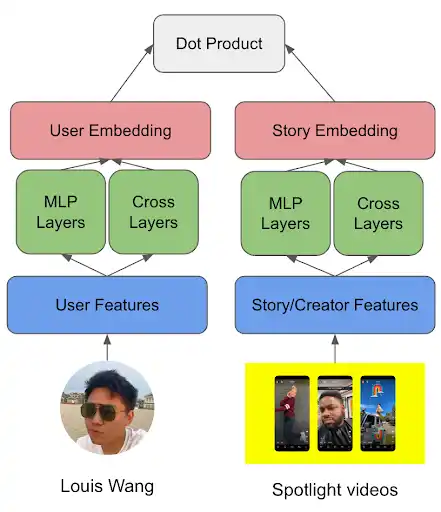
Figure 2. Overview of two-tower model structure
The representation layer really aims to enhance the complicated feature interactions from the outputs in the input layer. Here we use a ResNet-style neural network to combine the information after feature preprocessing and engineering. After concatenating the embeddings from sparse features and transformed values from the dense features, we feed them into an MLP layer and 4-layer deep cross networks, which are summed up as the final 128-dimension representation for each tower, called user embedding and story embedding respectively. In terms of optimization, the model uses the Adam optimizer, which adapts the learning rate for each parameter based on the first and second moments of the gradients and helps the model converge more quickly and avoid getting stuck in local minima. In addition, the model employs cosine annealing techniques with learning rate warming up, which gradually increases the learning rate from an initial value to the maximum value over a certain number of iterations at the beginning of training and reduces the learning rate over time to allow the model to converge smoothly.
The output layer combines the L2 normalized outputs from each tower with dot product operation, followed by a temperature factor, which makes the loss to be a hardness-aware loss and tends to penalize much more on the hardest negative samples.
The two-tower models are trained with user-story engagement signals where we combine multiple positive engagement signals (including boost action, long view action, favorite action etc.) together into one classification head. The users’ explicit feedbacks and implicit feedbacks supervise the two-tower models to generate meaningful and personalized embeddings. We take the cosine similarity followed by a sigmoid function, and apply binary cross entropy loss function to back propagate the two-tower neural network.
In terms of sampling, we add in-batch negative sampling to the model as we observe many stories are retrieved from countries/languages mismatched to the user if not. The effect is to use other users’ stories in the same batch as the current user’s negative examples. The idea is to let the model learn from more user-story combinations effectively and converge faster.
With two-tower models available, offline inference and online serving works together to make sure the Spotlight backend system retrieves relevant, personalized videos for users.
We use two dataflows to generate the embeddings for the two-tower models periodically. One is user embedding dataflow. It loads the basic information, recent activities, and engagement with different story types for each user, and then runs the user tower of the two-tower models to generate a user embedding for each user. This user dataflow runs every few hours to update the user embeddings pool. The other is story and creator embedding dataflow. It reads the available information about all stories (each story represents a video in our context) from the database, and then runs the story tower of the two-tower models to generate a story embedding for each story. This dataflow runs much more frequently to keep the freshness property of the story embeddings pool.
HNSW algorithm is used to build the ANN index with story embeddings. HNSW algorithm is a highly efficient algorithm for vector similarity search. The ANN Indexes are stored in Google Cloud Storage for retrieval service to load directly.
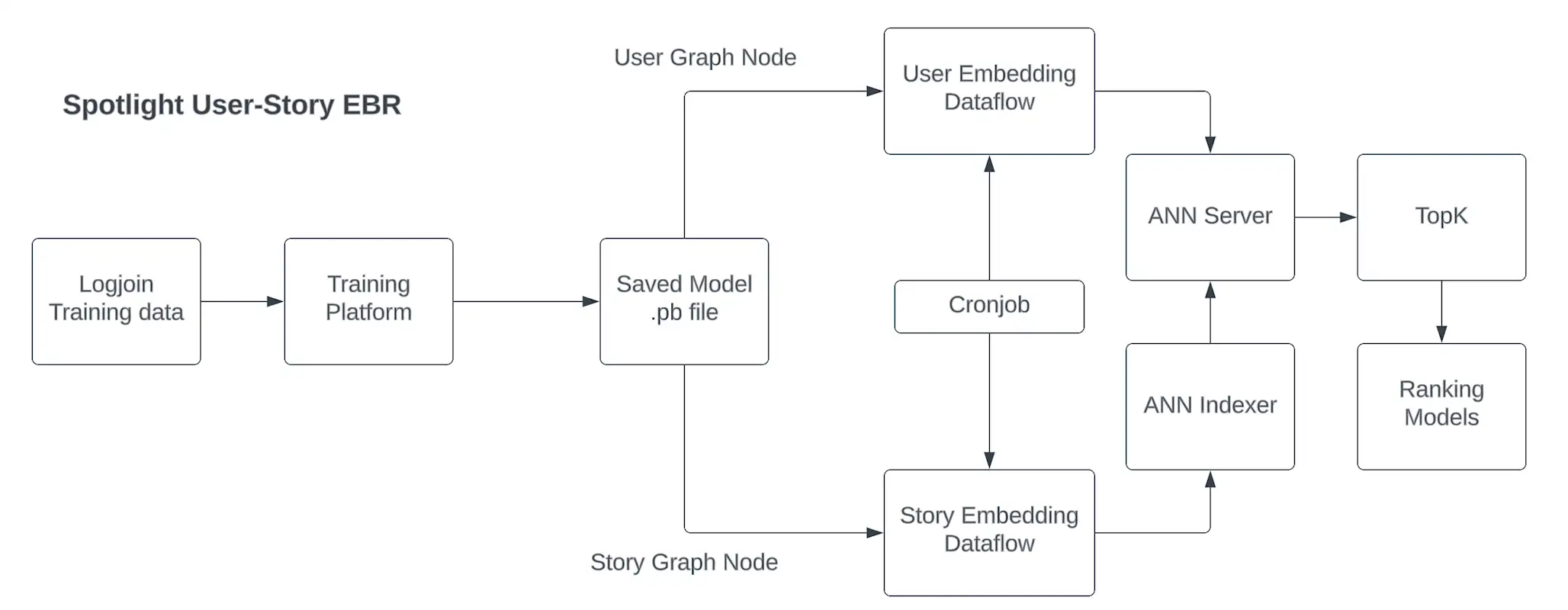
Figure 3. Overview of EBR Infrastructure and Serving
At the serving time, we retrieve user embedding through Snap’s user profile service and construct EBR queries. User embeddings are generated from the previously mentioned offline inference and loaded into the user profile service, which provides an API for the feed requests processing service. When client devices send prefetch requests or refresh requests, these events are handled by our feed requests processing service. Upon each request, the feed processing service retrieves the user embedding and sends the corresponding EBR queries to our retrieval service that queries the HNSW indexes.
We intentionally separated the feed processing services and retrieval service due to the difference in business logics and scalability requirements. Our feed processing service handles tens of thousands QPS for requests for not only Spotlight EBR queries but also dozens of other use cases so it intends to be a consolidated binary that handles different business logics. On the other hand, our retrieval service serves millions of story documents for EBR and other forms of requests thus it aims to be a sharded and scalable service. With this generic setup, we are able to serve multiple EBR models and handle various EBR request types.
After the great collaboration from multiple teams, and continuous efforts in this area, we not only achieve double-digit engagement gains in both views and view time for Spotlight, but also added many retrieval sources, including user-story EBR, user-creator EBR, similar creators and similar users, to provide personalized contents for later ranking stage, which bring more joy to snapchat users.
In the future, we will keep improving the two-tower models in the retrieval stage in a few directions. First, bigger and more complex models like Transformers. We will encode the user's sequence of engagement stories more efficiently through the transformer architecture, and try larger datasets to incorporate users’ long-term interests. Second, expand EBR to be the single and unified technique for all retrieval for better maintenance and cost saving.