
Synthetic Data for Machine Learning (ML)
At Snap we develop a large number of products and solutions powered by ML. Modern ML models require tons of high-quality data to be collected, labeled and processed. All these processes may frequently take a long time and lots of resources. In this post we talk about how we leverage synthetic data to boost the development of our ML models.
At Snap we develop a large number of products and solutions powered by ML. Modern ML models require tons of high-quality data to be collected, labeled and processed. All these processes may frequently take a long time and lots of resources. In this post we talk about how we leverage synthetic data to boost the development of our ML models.
One of the main goals for Snap developers is to provide all Snapchatters with unique, culturally relevant and diverse experiences. This is directly related to one of the major challenges to modern ML development - the structure and inner distributions of existing datasets. It implies:
Implicit biases – data is almost always skewed which leads to inherent biases related to gender, ethnicity, socioeconomic status, age, etc;
Unrepresented corner cases – collection of data samples for corner cases can be complicated and/or expensive, so model quality can suffer from the small diversity in data.
Manual data labeling is a very labor-consuming process. When it comes to large production datasets even ordinary labeling tasks such as segmentation or classification can cost hundreds of thousands of dollars per one dataset. Moreover, sometimes desired labeling can not be labeled at all and require complex and expensive data collection using special equipment (e.g. lighting environments).
Data being distributed with many different licenses, including ones restricted to only non-commercial use and so cannot be used.
We started by compiling a set of design principles:
Domain-agnostic: Since the range of potential applications is pretty wide, we need to have a pipeline that is able to process as many data domains as possible: human heads, bodies, cartoon characters, etc;
Easily expandable: data requirements from project to project usually vary, e.g. some of them require a special light setup, others don't. So we need a system that provides a functionality like a constructor;
Based on the listed requirements, we decided to implement a Synthetic Data Generator based on a set of building blocks, each of which have the same interface and augment a single 3D scene.
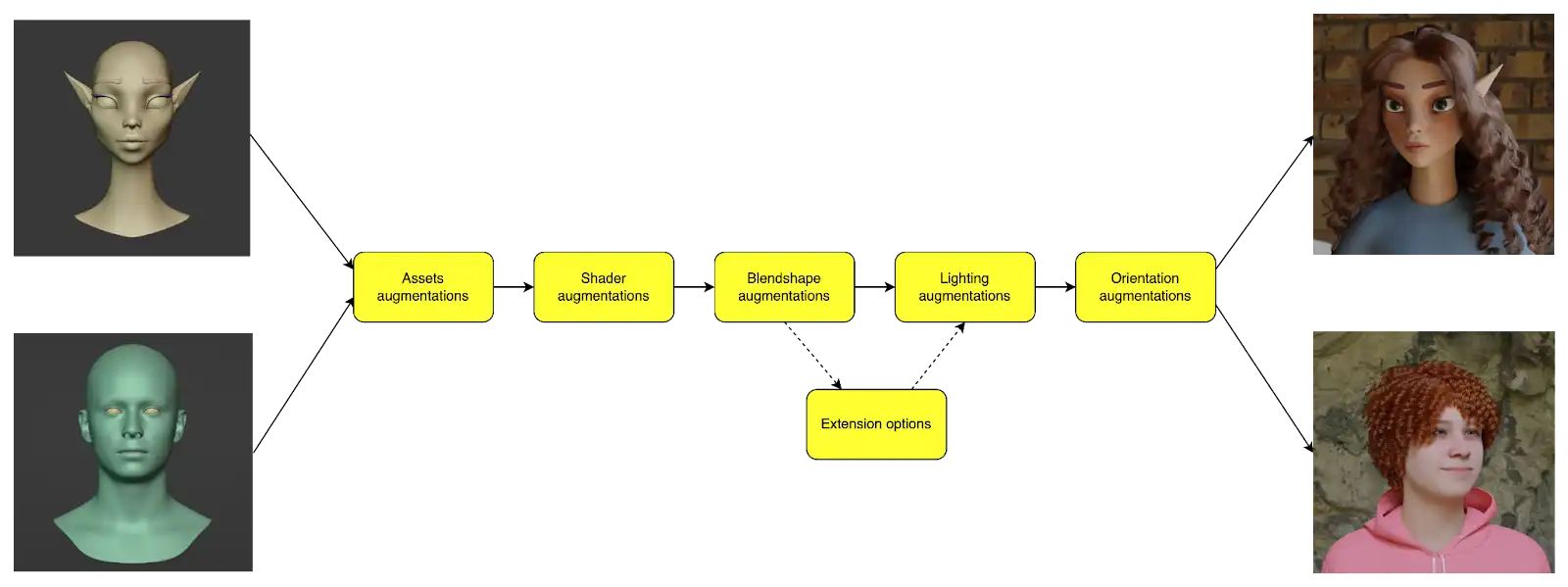
As the input pipeline takes a base model (3D sculpted model or 3D scan) which is being added to the scene.
One of the most important building blocks:
1. Asset Augmentations
An asset is basically any object being somehow attached to the base model. It can be a haircut, clothes, etc. Assets of each type can contain unique logic of attaching, but in most cases we use a proxy object that provides the correct location where the asset needs to be placed.

2. Shader Augmentations
This type of augmentation aims to improve all essential textures for the Base Model and added objects, such as skin, eye and hair color, all of which are important for providing a diverse dataset.
The first step is creating a set of textures for each Shader Augmentation.
Examples of skin textures:

Examples of eye textures:

The second step is to align the collected textures with the Base Model so that they are neatly overlaid. After doing so, we are able to generate a diverse set of objects with the same Base Model but with varying skin colors, eye colors and so on.
3. Blendshape Augmentations
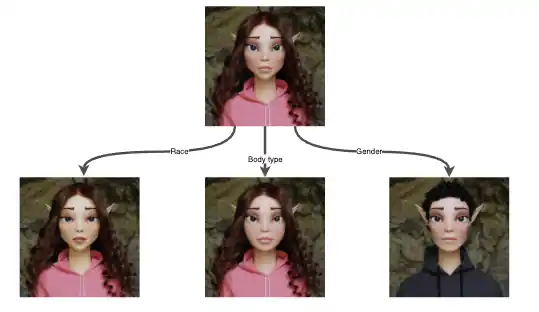
Blendshapes augmentations allow us to change a Base Model’s gender, race, body type and facial expressions by adjusting the face geometry. For each Base Model , we create a set of blendshapes to implement essential facial transformations, such as smiling and blinking eyes.
By adding such blendshapes, we can generate data with different face geometries containing identifiable traits for different ethnicities, body types and genders:
To make the ML models robust for all face emotions, we should also add as many facial expressions as possible to the dataset: mouth expressions, eye blinks, brow emotions, etc:

The required set of blendshapes differs slightly from task to task. For example, for cartoon characters generation we compiled the following list of required blendshapes:
Gender (feminine ↔︎ masculine face features)
Eyes:
Gaze direction change
Eye blinking
Mouth expressions:
Sad
Smile
Laugh
Kiss
Wide Smile
Surprised
Extremely opened mouth
Brows:
Raise eyebrows
Lower eyebrows
4. Lighting Augmentations
ML models are usually quite sensitive to the lighting environment on which they are inferred. The model will fail on images with dark and shady light if it is trained on a dataset with images with only bright light. Lighting augmentation is one of the most common augmentations for improving data diversity. It allows us to generate heads in a variety of lighting conditions, including bright, dark, and shaded conditions. In general, there are two different ways for lighting augmentation:
HDRI lighting
HDRI lighting - panoramic photo, which covers all angles from a single point, that can be used to apply lighting to 3D models. Furthermore, employing HDRI allows us to augment the background of created images at no cost. Examples of HDRIs and the samples created with them are:

Light scene
Another way to set lighting is to create a light scene. This method involves considerably more work because each scene must be constructed separately, but it provides much more control over the lighting environments. We can add various light sources (such as lamps) and adjust their locations in the scene. Here is an example of images rendered with different light scenes:

The default option for Light Augmentations is HDRI augmentation, but light scenes can be employed if a more precise and customized lighting environment is desired for the generated object.
5. Orientation Augmentations
An ML model must perceive training items from all viewpoints that it may encounter in real life to achieve generalization. This is why we included Orientation augmentation, which allows us to rotate the Base Model along the Pitch and Yaw axes, allowing us to move the model up and down as well as left and right. Because our ML models process the crop of the user's head, which forces the Roll angle to be zero, we do not need rotation along the Roll axis.
We added an Anchor object behind the head and tied it to the Base Model in such a manner that the model always “looks” along the vector V heading from the Anchor object to the location on the back of the head to create the required rotation system. The Anchor object is depicted as a ball, while the dotted blue line represents vector V:
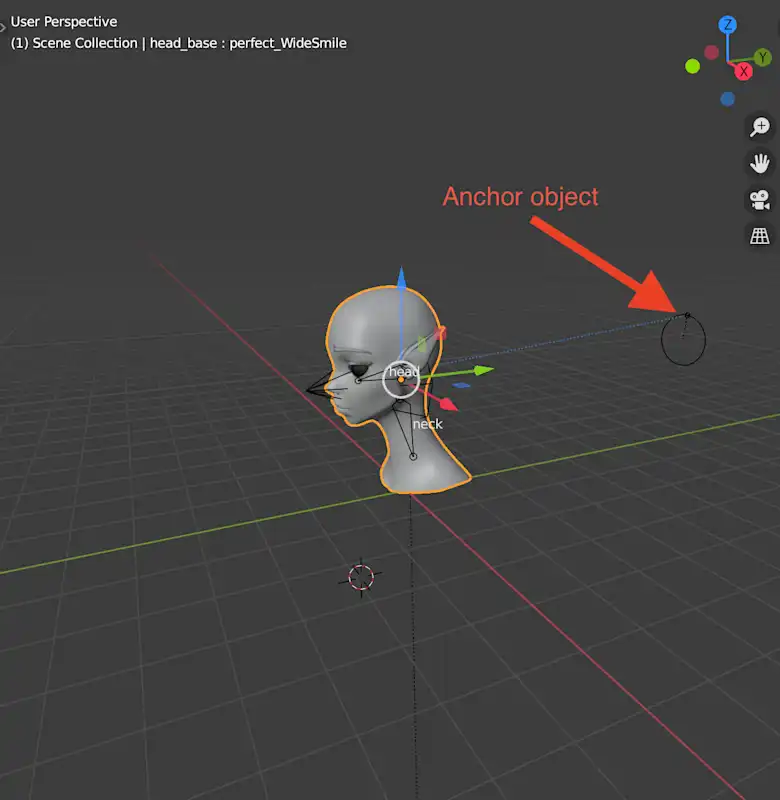
We then created an animation that draws a circle C on a plane defined by the Pitch and Yaw axes. The Anchor object, consequently, makes a full turn over C, increasing the radius of C. The rotation system is developed in such a way that the final dataset's distribution of rotations covers real-life rotations by a margin. The left gif depicts how C is being changed, whereas the right gif depicts how the rotations are perceived from the camera's viewpoint:
Lenses as a part of the AR platform is one of the most popular products of Snap Inc with hundreds of millions of daily users. Unlocking new instruments for releasing new Lenses is very important for us.
Based on describe pipeline we are able to create Snapchat Lenses:
Elf Lens:
Big Smile Lens

To make 3D and 2D assets in Snapchat AR products look more realistic and natural, Snap developed a Dynamic Environment Map feature for Lens Studio. This feature estimates lighting on a user's face and applies it to the AR objects.

Follow Snap on LinkedIn to learn about new products and life at Snap!